

Digital experiments serve a large variety of purposes. You may want to learn whether you’re building the right thing, you might want to safely release changes without introducing regressions, or you might just want to pick a winner between some easy-to-build options.
But one tool won’t be best for all of them. A classic A/B test might struggle if you throw 10 options at it, or it might take too long to reach a clear result if your goal is just to do no harm.
That's why GrowthBook provides you with 3 different tools, all powered by our state-of-the-art statistics engine and performant SDKs.
Experiments for learning, Safe Rollouts for releasing safely, and Bandits for picking a winner among many.
When to use a classic Experiment
Use classic Experiments when you want to:
- Build a better product or website
- Learn about customer behavior as accurately as possible
- Choose from only 2-3 different options, or a few options that were costly to build with respect to time from design, engineering, and product
Classic experiments in GrowthBook are great at providing you the clearest answer to the difference in your key goal metrics between 2 or 3 variations. For instance, if you've spent weeks designing and building a new checkout flow, you need precise measurements of how it affects conversion rates compared to your current design.
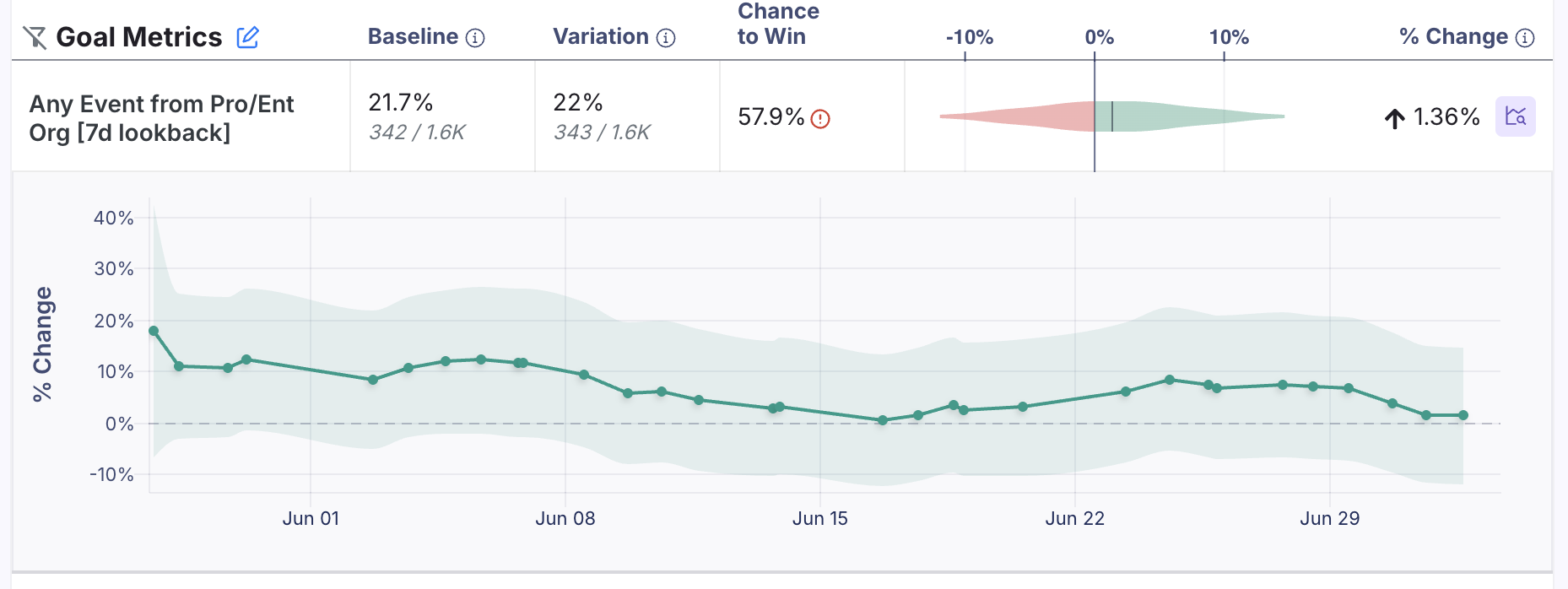
You can reduce variance using tools like CUPED. Or, you can use sequential testing and multiple comparisons corrections to best balance false positive rates and faster shipping. You can also add Dimensional analyses to slice-and-dice your results and learn more about how what you are building affects your users.
Furthermore, classic Experiments provide accurate experiment effects that form the basis for a historical library. This data becomes invaluable for driving Insights about the overall performance of your product development.
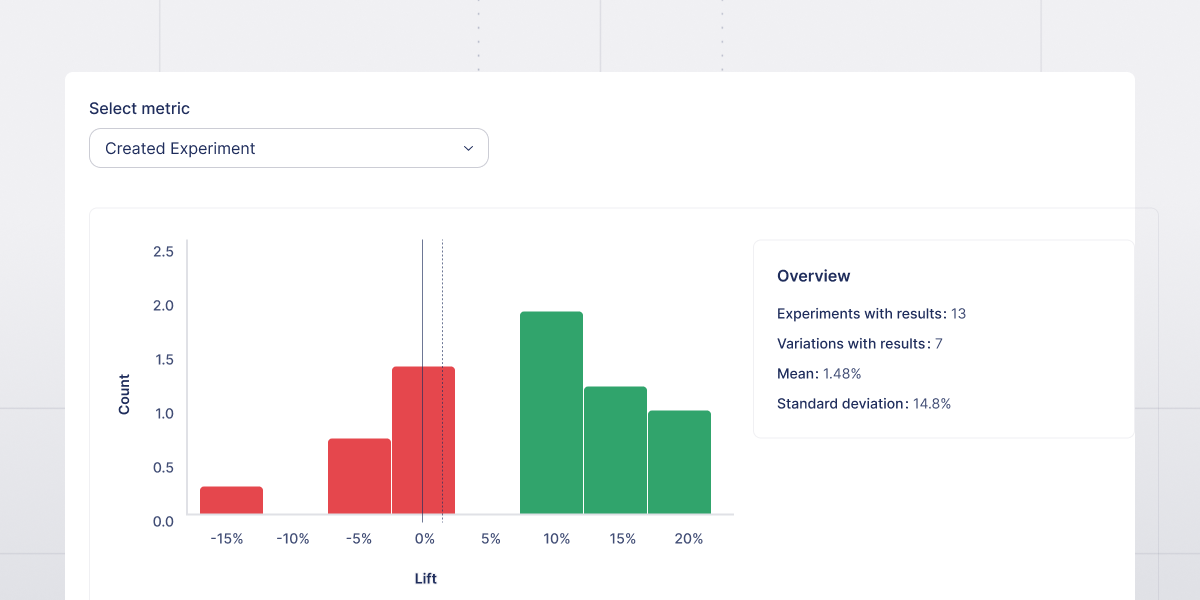
When to use a Safe Rollout
Use a Safe Rollout when you want to
- Release confidently by rolling back as soon as there is a clear regression
- Ship automatically as long as you're doing no harm
- Do lightweight experimentation with every release
Safe Rollouts are built right into GrowthBook Feature Flags and are fast and easy to set up. They use one-sided sequential tests and automatic traffic ramp-ups to ensure that when a guardrail fails, your feature rolls back without inflated false positive rates. This way you can make experimentation a part of every release.
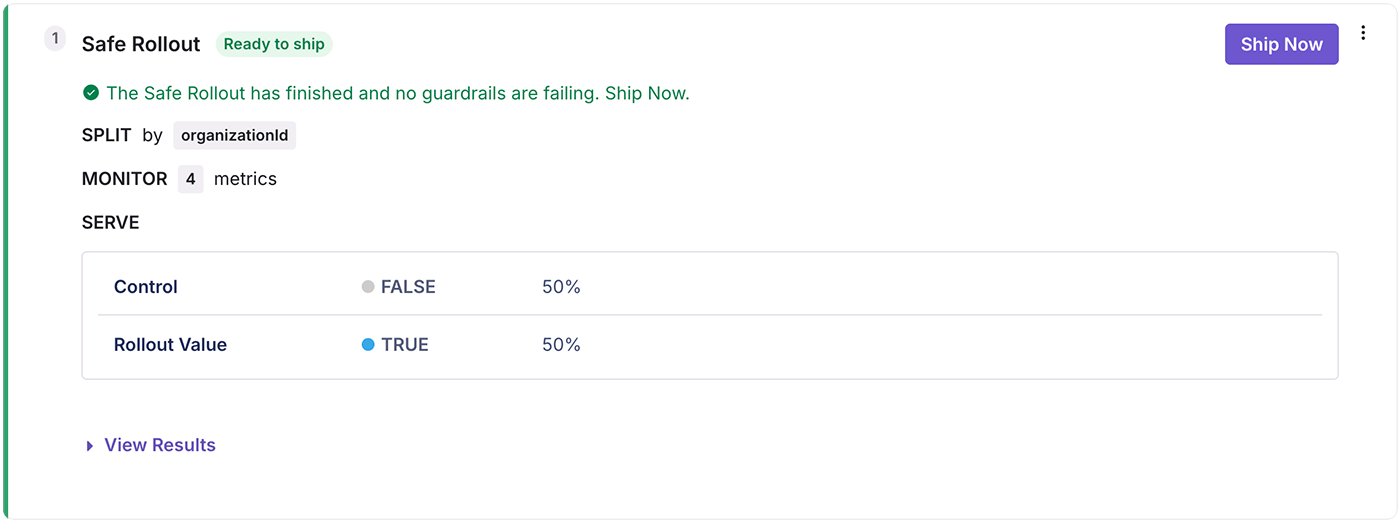
Imagine you've refactored an API endpoint for better performance. Your goal isn't to learn whether it's 5% or 8% faster. You just need confidence it won't break anything. Safe Rollouts lets you release to 5% of users, automatically scale up if metrics look healthy, and instantly roll back if error rates spike.
While Safe Rollouts can more confidently flag early regressions than a classic Experiment, they aren’t as fine tuned for building up a library of effects or getting exceedingly precise estimates. They do use CUPED, but it is used in service of detecting regressions more quickly, not getting the most precise overall lift. Safe Rollouts are also restricted to just 2 variations since they’re designed to safely release a new feature, rather than test between multiple arms.
When to use a Bandit
Use a Bandit when you want to:
- Pick a winner between 4+ different variations that were easy to build
- Reduce traffic going to variations that are struggling early in an experiment
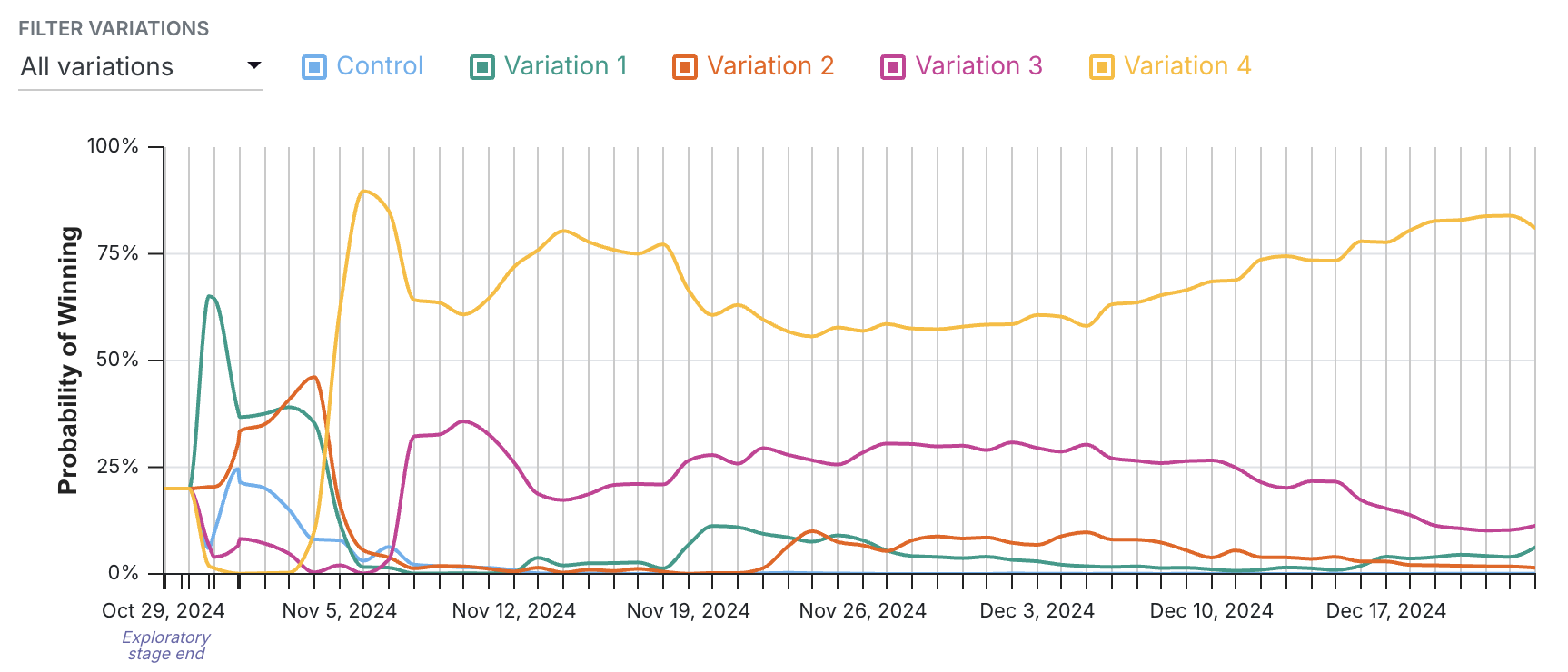
Multi-armed Bandits optimize traffic in an experimenting by directing more traffic to better performing variations. For example, you're running a week-long sale and you want to test out different CTAs. By the time you completed a classic Experiment, the sale would be over and you would've lost out on sales. With Bandits, traffic automatically shifts toward the winning CTA during sale, maximizing conversions.
This provides dual benefits: better variations get more statistical power from increased traffic, while fewer users see worse-performing options, protecting your bottom line.
GrowthBook’s Bandits stand apart from the field by ensuring a consistent user experience during the bandit and by using period-specific weighting to deal with seasonality (e.g., day-of-the-week effects) in your experiment sample. However, Bandits in general are known to suffer from some inaccuracies at providing top-level estimates of experiment lifts, so they are best suited for picking a winner among many, instead of learning precisely how much a variation outperformed another.
GrowthBook provides the tools you need
All 3 forms of experimentation, classic Experiments, Safe Rollouts, and multi-armed Bandits, use the power of randomization and GrowthBook’s state-of-the-art statistics engine to provide you with the right answers to the right questions.
Ready to choose the right experimentation approach for your next project? Get started with GrowthBook in under 5 minutes.



