
A feature flag platform ends up in critical paths: request handlers, render paths, mobile startup flows, and incident response. Most development teams still evaluate tools by feature checklists and pricing pages. That misses what tends to matter after adoption: runtime behavior, failure modes, testability, and whether measurement becomes a second system of record.
This article compares GrowthBook and LaunchDarkly across three architectural planes that tend to matter more than feature checklists:
- Runtime plane: How flag definitions propagate, how targeting decisions are evaluated, update models, hot-path dependencies, and outage behavior.
- Measurement plane: How rollout exposure connects to outcomes, and whether measurement becomes a second system of record.
- Control plane: Governance, approvals, environments, enterprise integrations, and deployment model.
Each section focuses on real-world behavior and operational tradeoffs, not feature checklists. Both platforms cover the control-plane basics and provide rollout safety features, but they optimize for different priorities.
LaunchDarkly tends to win when you want observability-connected safety automation and enterprise workflow/compliance plumbing (ServiceNow, Terraform, broader certification programs).
GrowthBook tends to win when you want deterministic local evaluation, SQL-native impact measurement aligned with your database or warehouse, self-hosting options, and seat-based pricing predictability.
Pick based on whether you prioritize managed safety and workflow automation or runtime predictability and measurement alignment with your existing data systems.
The three planes of feature flagging
Every feature flag platform operates across three planes:

Diagram 1: The three planes of feature flagging
Control-plane features are easy to compare; runtime and measurement are where long-term debt accumulates.
GrowthBook vs LaunchDarkly: Runtime, Measurement, and Control Planes Compared
| Plane | What matters | GrowthBook (typical) | LaunchDarkly (typical) |
|---|---|---|---|
| Runtime | Hot-path dependency, caching, failure modes, targeting flexibility | Local rule evaluation; attribute-driven targeting without schema changes | Relies on LD services for rule storage; multi-context targeting with explicit entity modeling |
| Measurement | Joining exposure to outcomes, avoiding "two truths" | SQL-native measurement against your database/warehouse | Event collection with export paths; warehouse-native options vary by offering |
| Control | Rules, environments, approvals, governance, deployment | Strong baseline; self-host option; single-stage approvals | Deeper enterprise workflow plumbing (ITSM/IaC); multi-stage approvals; broader certifications |
Runtime plane: updates, evaluation, and targeting
Feature flags live in hot paths and incident loops. When you evaluate feature flagging platforms, start with four runtime questions:
- How do updates propagate? (polling vs streaming; how fast can you change a rollout?)
- What's on the hot path? (local evaluation vs remote dependency; where does latency come from?)
- What happens in partial outages? (what's cached; what degrades; what falls back to defaults?)
- How flexible is targeting? (can you add new dimensions without refactoring your identity model?)
The first three are pure runtime concerns. Targeting spans both the control plane (where you define rules) and runtime (where those rules get evaluated). Below is how GrowthBook and LaunchDarkly answer these questions in practice.
Update propagation (polling vs streaming)
How do flag changes reach running apps? This matters when you're expanding a rollout or killing a flag during an incident.
GrowthBook: SDKs fetch and cache the rules payload locally at initialization and can refresh it periodically or on demand. If you need faster propagation, the GrowthBook Proxy or GrowthBook Cloud supports streaming updates via Server-Sent Events.
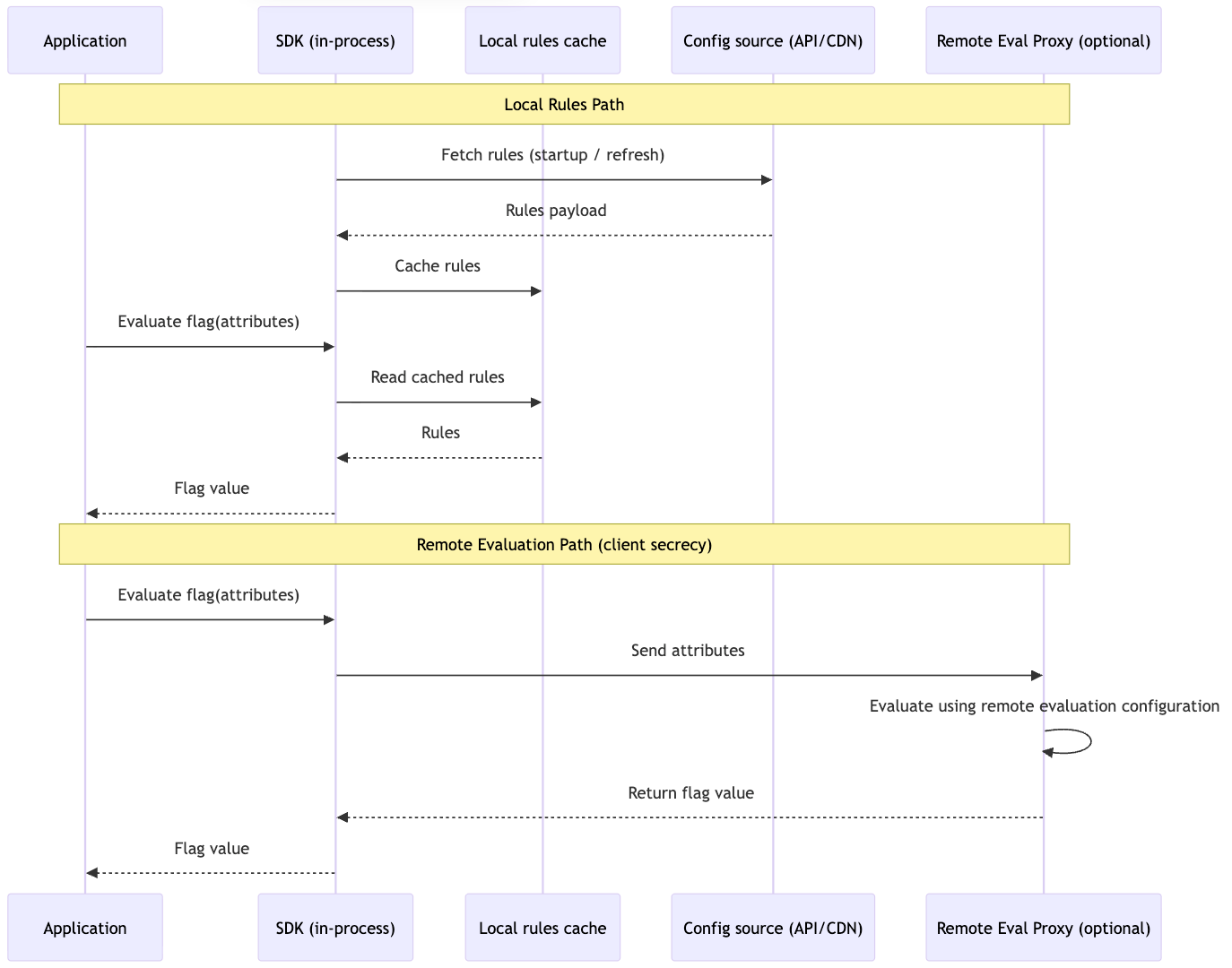
Diagram 2: GrowthBook SDKs Runtime Evaluation Flow
LaunchDarkly: Server-side SDKs commonly use streaming connections for updates. Client-side SDKs may poll or stream depending on platform and configuration.
What to take away: GrowthBook is “fetch-and-cache by default, stream when needed.” LaunchDarkly is “streaming-first” in many deployments.
Hot-path dependency (local rules vs remote evaluation)
GrowthBook: Often uses a cached-rules model: SDKs fetch a rules payload, keep it locally, and evaluate in-process. If you need to keep targeting rules off the client, GrowthBook supports Remote Evaluation mode via the proxy/edge workers.
LaunchDarkly (client-side): Client-side SDKs rely on LaunchDarkly services to store flag rules and deliver flag values/updates for a specific context, reducing rule exposure but increasing network dependence during init/refresh.
What to take away: Rule secrecy and centralized evaluation usually implies more network reliance; local rules reduce dependency surface area.
Partial outages and degradation behavior
Both platforms cache locally, but what’s cached determines the failure mode:
- GrowthBook client-side (local rules): SDK caches the ruleset. During an outage, evaluation continues from cached rules; you mainly lose propagation of new changes.
- LaunchDarkly client-side (local values): SDK caches evaluated values for a context. During an outage, cached values continue to serve; evaluations that require fresh context updates may fall back to defaults until connectivity is restored.
- Server-side (both): SDKs typically cache rules locally and evaluate without network calls; outages mostly affect receiving updates.
What to take away: The practical difference is whether the client can keep evaluating against rules offline (rules cached) versus only serving previously-evaluated values (values cached).
That covers how flags arrive and evaluate in production. The next runtime question is what you can express with those evaluations: targeting.
Targeting: who sees what, and how flexible is the model?
Targeting determines who sees what when a flag is evaluated: by user, tenant, region, device, plan, or any other attribute.
Targeting straddles both runtime and control planes. You author rules in the control plane, but they execute at runtime. We cover it here because the runtime model (how rules get evaluated, what you can express without SDK changes) is where GrowthBook and LaunchDarkly differ most. The control-plane authoring experience is comparable; the runtime flexibility is not.
Tenant-consistent rollouts for B2B
B2B SaaS teams need rollouts that are consistent per tenant. If you're testing billing changes on 10% of organizations, User A and User B from Acme Corp need to see the same thing.
GrowthBook: hash-based bucketing on any attribute. Set the hash attribute to company_id and all users from the same company land in the same bucket. No state synchronization required.
“We were looking to customize attributes on which we could toggle a roll-out, instead of using a percentage roll-out. Having tags for the classroom or the district a student is in, and then actually rolling out based on those, gives us a lot more power.”— John Resig, Chief Software Architect, Khan Academy, customer story
LaunchDarkly: multi-context targeting. Define explicit context kinds (user, organization, device) and build rules that compose them. More structured but requires more upfront modeling.
Composition vs. Structural Identity
LaunchDarkly: multi-contexts model User, Organization, and Device as distinct entities. That helps when those entities have separate lifecycles, metadata, and policy rules.
GrowthBook: keeps the runtime model simpler: evaluation is driven by the attributes you pass (for example company_id, plan, device, region), and you can compose reusable targeting logic with Saved Groups (including nested groups) instead of introducing entity schemas at the SDK level.
When to choose
Choose GrowthBook if: You expect targeting dimensions to change over time and you want to add new ones without introducing new context schemas or SDK-level entity modeling.
Choose LaunchDarkly if: You need explicit, first-class separation between entity types (user vs org vs device) and you want targeting/governance to reflect those boundaries directly.
Measurement plane: proving rollout impact
Measurement determines whether you can reliably connect who saw a change with what happened next. The integration model matters because it either reuses the metrics and data pipelines your team already trusts, or creates a second analytics system that can drift from your source of truth.
When toggles aren't enough
You ship a feature behind a flag to 20% of users. A week later, your PM asks: "Did it increase conversion?" Your VP asks: "Did it slow page loads?"
Now flags become an analytics problem. You need to join flag exposure (who saw what variant) with outcomes (revenue, latency, errors).
When flag platforms become a second source of truth
Many centralized experimentation and flag platforms collect events via SDKs, store them in their infrastructure, and provide dashboards for analysis. To join rollout data with your product analytics or warehouse, you use Data Export (sometimes an add-on depending on plan) and build pipelines.
This creates two problems:
- Duplicate instrumentation. Sending events to your analytics platform (Amplitude, Mixpanel, your warehouse) AND your flag vendor. Duplicate tracking code, duplicate schemas, potential drift.
- Metric drift. Vendor analytics calculates revenue one way. BI team calculates it another. Results don't match. Trust erodes.
If your product data already lives in a central database or warehouse, a second analytics system can introduce unnecessary drift and duplication.
How the two platforms approach this:
LaunchDarkly: Collects flag exposure events into its own system and provides analysis there. To analyze outcomes using your warehouse metrics, you typically export those events and join them downstream.
GrowthBook: Reads exposure and outcome data directly from your database or warehouse and computes results with SQL, so the experiment uses the same tables and metric definitions your BI and engineering teams already rely on.
SQL as a simplifier
GrowthBook's approach: compute outcomes using SQL against your existing database. Flag exposure and outcome analysis stay aligned with the metrics and joins your team already trusts.
How it works:
- Define metrics in SQL against tables that already exist in your database.
- GrowthBook runs those queries to calculate results.
- All data stays in your database. No export, no pipelines, no schema mapping.
Postgres/MySQL as the practical on-ramp
"Warehouse-native" can sound like you need Snowflake or BigQuery to get started. You don't. If you're running Postgres or MySQL for your application, GrowthBook can use those directly as your measurement database. This lets engineering teams start with outcome measurement without waiting for data warehouse infrastructure or analytics team support.
Practical setup:
- Connect GrowthBook to a read replica (not your production primary). Cap time windows to avoid full table scans.
- Define a Fact Table with a single SQL query, then derive multiple metrics from it using the metric builder. For advanced cases, drop to raw SQL.
As query volume grows, the same SQL-defined metrics can move from Postgres to ClickHouse or your preferred warehouse without rewrites. GrowthBook supports multiple SQL data sources including Postgres, MySQL, ClickHouse, Snowflake, BigQuery, Redshift, and Databricks.
Practical benefits of warehouse-native measurement
Use metrics you trust. Your BI team has a revenue metric. Your data engineers validated it. Use that in rollout analysis instead of reimplementing it in a vendor dashboard.
Measure engineering outcomes without instrumentation. You have error logs in BigQuery. Write a metric that counts errors by flag variant. No SDK events, no custom tracking. Just SQL against existing tables.
Tail metrics with statistical validity. If you already store latency or error telemetry, GrowthBook can attribute changes to rollout exposure using the same analysis pipeline as your other metrics. P95/p99 and tenant-level effects get measured at the right unit, not eyeballed from a graph.
Tenant-correct measurement for B2B. GrowthBook can measure rollout impact in a way that respects tenant boundaries, so you don't accidentally treat thousands of users in one large customer as thousands of independent samples. LaunchDarkly can get you the exposure data, but tenant-correct impact measurement is something you typically implement yourself downstream.
LaunchDarkly's approach
LaunchDarkly's Data Export sends raw events to your warehouse. You can then write SQL to join them with your metrics. This approach works, but it introduces an additional pipeline to maintain.
LaunchDarkly has now started offering warehouse-native experimentation capabilities for Snowflake. Availability and feature scope may vary by plan and region.
Control plane: governance and deployment
Operational constraints determine how a flagging platform fits into your organization’s security model, change-management processes, and cost structure. These factors often matter less during early adoption, but become decisive as teams scale, enter regulated industries, or standardize release workflows across the company.
Governance and deployment
Standard controls
Both platforms support staged rollouts, approval workflows, and RBAC. GrowthBook has single-stage approvals. LaunchDarkly supports multi-stage approvals (up to five stages). Most teams find single-stage sufficient. Regulated industries or large organizations with complex change management may require multi-stage.
Environments work similarly: dev, staging, production. You can copy flags across environments and test changes before promoting to prod.
Self-hosting and data perimeter control
GrowthBook is open source and self-hostable. Run the entire platform in your VPC, keep all data in your infrastructure, never send PII to a vendor. Deployment via Docker, Kubernetes, Helm.
LaunchDarkly is a multi-tenant SaaS. Relay Proxy exists for edge caching, but the management and control plane remains SaaS. For air-gapped deployments or zero data egress requirements, GrowthBook is the option between these two.
"With the kinds of experiments we run and the sensitive data we handle, data security is paramount. The fact that GrowthBook offered us the ability to keep that data in-house was a key reason why we chose to work with them."— Diego Accame, Director of Engineering, Growth, Upstart, customer story
Where LaunchDarkly's enterprise integrations matter
LaunchDarkly has native ServiceNow integration, a mature Terraform provider, and compliance certifications (ISO 27001, ISO 27701, FedRAMP). For organizations that require ServiceNow change management, Terraform for infrastructure-as-code, or specific compliance attestations, these are table stakes.
GrowthBook has SOC 2 Type II. LaunchDarkly’s additional certifications will matter to some teams selling into highly regulated industries. For teams without these specific requirements, these certifications won’t be necessary.
That covers the three architectural planes. But there's one more dimension that doesn't fit neatly into the model, and it often ends up mattering more than teams expect.
The hidden dimension: pricing (dis)incentives
The three-plane model covers the technical evaluation. But there's a fourth dimension that doesn't fit neatly into architecture diagrams: pricing. Most teams treat it as a procurement problem, separate from technical decisions. That's a mistake.
Pricing models shape how teams use platforms. They create incentives that ripple back into architecture.
LaunchDarkly prices their product based on monthly active users (MAU) for client-side and service connections for server-side (per LaunchDarkly's pricing page). As your user base grows, your bill grows. At scale, MAU-based pricing can push teams to architect around counting and routing rather than shipping: sampling, filtering, or proxying traffic to manage cost. The platform becomes a line item that scales with success, which can create tension between "flag everything" best practices and budget constraints.
GrowthBook prices per seat with unlimited flags, traffic, and experiments (per GrowthBook's pricing page). The bill is the same whether you have 100K users or 10M users. This removes the "should we flag this?" calculation. Teams use flags more liberally because there's no marginal cost per evaluation, which can lead to cleaner release processes and faster rollbacks. This allows team to deploy feature flags at scale much more cost effectively.
This isn't about which model is "better." It's about recognizing that pricing affects architecture. If your team is already optimizing flag usage to manage costs, that's a signal worth examining.
How to decide
When GrowthBook is the better fit for development teams
- Flag evaluation off the network hot path. GrowthBook's local evaluation model keeps decisions in-process with cached rules, reducing dependency surface area and making failure modes easier to reason about.
- Identity model changes frequently. Attribute-driven targeting lets you add new dimensions (tenant, plan, cohort, region) without introducing new context schemas or SDK-level entity modeling.
- Rollout impact measured in SQL on data you already trust. GrowthBook computes metrics directly against your Postgres, MySQL, or warehouse tables, avoiding a second analytics system and metric drift.
- Self-hosting or strict data-perimeter control. GrowthBook can run entirely inside your VPC with no PII leaving your infrastructure.
- Predictable, seat-based pricing. Costs stay stable as traffic grows, which removes incentives to sample or proxy requests just to manage MAU.
When LaunchDarkly is the better fit for development teams
- Auto-generated metrics from observability platforms. LaunchDarkly can auto-generate metrics from OTel traces and observability tools (Dynatrace, Honeycomb, New Relic, Splunk). This reduces setup time when you want rollout safety tied immediately to production telemetry. GrowthBook has Safe Rollouts with auto-rollback as well, but guardrail metrics are SQL-defined, which means routing observability data to your database or warehouse first.
- ServiceNow/ITSM governance is mandatory. LaunchDarkly has native ServiceNow integration. GrowthBook uses webhooks and APIs.
- ISO 27001, ISO 27701, or FedRAMP certifications are required. For teams selling to federal agencies or highly-regulated industries, these certifications are non-negotiable.
- Terraform provider is mandatory. LaunchDarkly has a mature Terraform provider for infrastructure-as-code workflows. GrowthBook doesn't.
- Niche or legacy SDK coverage. LaunchDarkly supports platforms like Haskell, Erlang, Roku, and Apex. GrowthBook's 23 SDKs cover most platforms but not these.
Decision guide
| Priority | Recommended Feature Flagging Platform |
|---|---|
| Runtime dependency surface (hot path, outages, testing) | GrowthBook |
| Flexible targeting without refactors | GrowthBook |
| Self-hosting / data perimeter control | GrowthBook |
| SQL-native measurement (database/warehouse) | GrowthBook |
| Seat-based pricing predictability | GrowthBook |
| Experimentation rigor (quantile, CUPED, cluster) | GrowthBook |
| Release safety automation (guarded rollouts, auto-rollback) | Both |
| Auto-generated metrics from observability platforms | LaunchDarkly |
| Enterprise compliance (ISO, FedRAMP) | LaunchDarkly |
| ITSM workflows (ServiceNow) | LaunchDarkly |
| Infrastructure-as-code (Terraform) | LaunchDarkly |
| Niche SDK coverage (Haskell, Erlang, Apex) | LaunchDarkly |
Bottom line
Feature flagging looks simple on the surface. Development teams discover the real differences once flags sit in their hot paths, incident response, and product metrics.
At runtime, the question is how much of your flag evaluation depends on network and vendor infrastructure. GrowthBook leans toward local, deterministic evaluation. LaunchDarkly leans toward managed infrastructure with deeper built-in safety automation.
In measurement, the question is whether rollout impact lives inside the flag vendor or stays aligned with the database and metrics your team already trusts. GrowthBook centers measurement in SQL on your existing systems. LaunchDarkly centers it in a managed event and observability pipeline, with export paths when you need them.
In operational constraints, the question is whether you need enterprise workflow plumbing and compliance programs out of the box, or control over deployment, data location, and cost structure.
Both platforms cover the control-plane basics. They optimize for different failure modes and organizational priorities. The right choice isn't about feature checklists. It's about which architecture matches how your systems fail, how your data is measured, and how your organization ships software.