
Kelli Hill gave a standout presentation at The Conference known as Experimentation island on February 24, 2026, walking the audience through Khan Academy's evolution from intuition-based testing to running A/B tests on generative AI features in production. If you missed it, the good news is Kelli will be joining us for a webinar on April 16, 2026. I'd highly encourage you to register here. Below are my key takeaways from her talk.
A Quick Word on Khan Academy
Khan Academy is a nonprofit with a mission to provide a free, world-class education for anyone, anywhere. They have nearly 200 million registered users and have logged over 63 billion learning minutes on their platform. In 2023, they launched Khanmigo, a generative AI-powered tutor and teaching assistant built on top of their massive library of exercises, articles, and instructional content. Khanmigo is the focus of much of their current experimentation work, and the context for everything Kelli shared.
From Homegrown to a Real Experimentation Stack
Khan Academy has been running experiments since 2011, when they built their first in-house platform on Google App Engine. At their peak, they had hundreds of A/B tests running simultaneously. But over time, the homegrown system slowed down, and when they rewrote their entire backend in 2019 (a million lines of code, migrating off Python 2), they made a deliberate decision not to port their old experimentation tooling.
Instead, they evaluated what was available. Building a new platform in-house was tempting, but they recognized that experimentation infrastructure wasn't their core competency. Buying an enterprise solution would have required downsampling their data, which was a non-starter. They ultimately chose GrowthBook, self-hosting it and connecting it to their existing data warehouse and eventing pipelines. Their chief architect's top priority was that the tool not slow down a site serving a million daily active users, and GrowthBook delivered on that.
The lesson here is one we see repeatedly: organizations that try to build their own experimentation platform almost always end up spending more than expected, moving slower than they'd like, and eventually switching to something purpose-built. Khan Academy's journey is a textbook case of making that transition well.
How Evals Evolved from Vibes to Automated A/B Testing
The most fascinating part of Kelli's talk was the four-phase journey Khan Academy went through to figure out how to measure AI quality. When you're building an AI tutor, you can't just measure click-through rates. The goals are harder:
- Increased cognitive engagement
- An increase in skills on their way to proficiency
- Measurable learning gains on external assessments.
And LLMs make measurement even harder because they're non-deterministic. The same prompt can produce wildly different outputs each time.
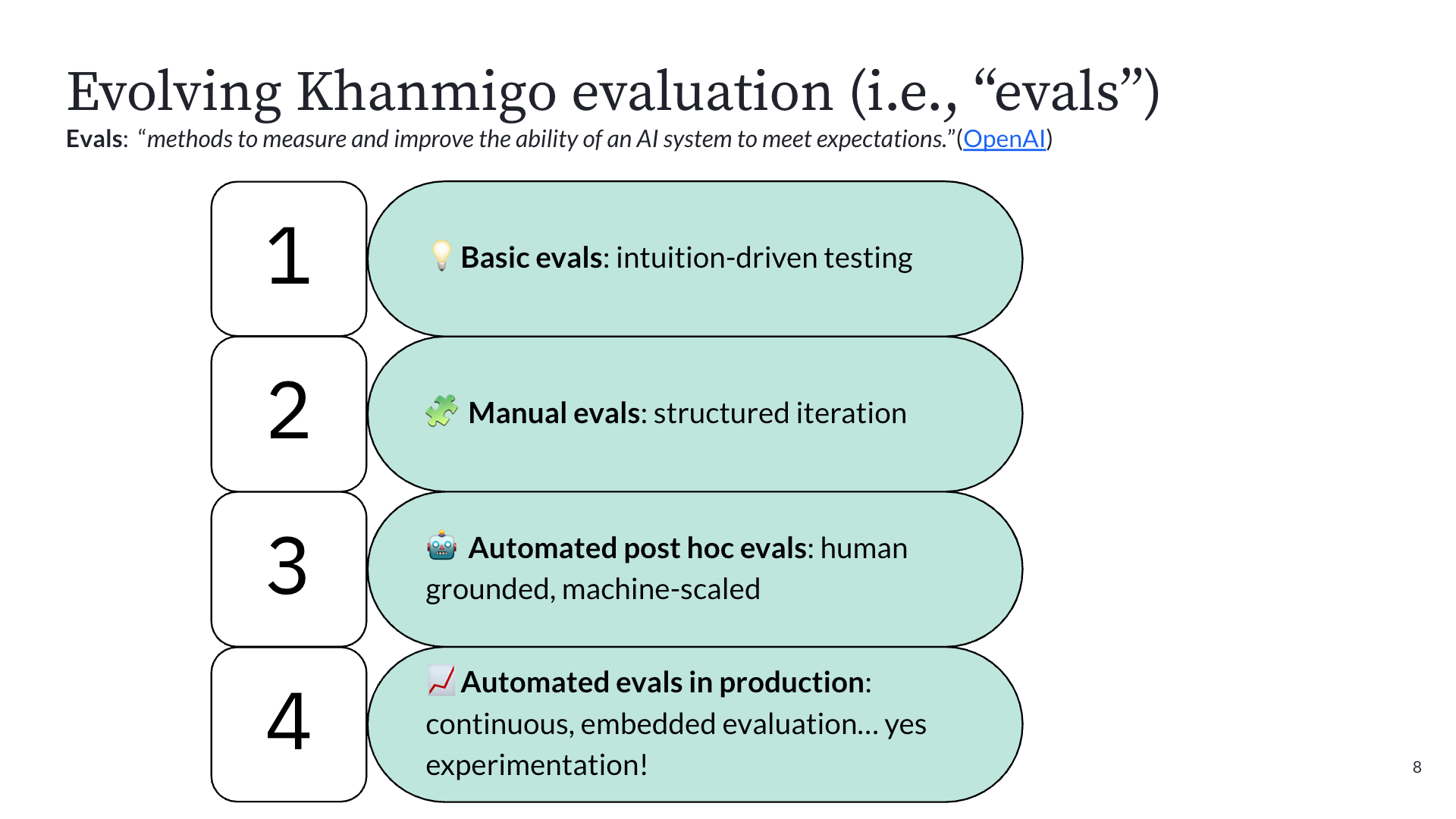
Phase 1: Intuition-driven testing. In September 2022, before ChatGPT had even launched publicly, OpenAI gave Khan Academy early access to GPT-4 via Slack. The team's first experiments were literally typing prompts into Slack and reading the outputs. They quickly discovered problems (GPT-4 confidently told a user that 9 + 5 = 15, then gave the correct answer ten minutes later). Good enough for building intuition about how LLMs behave, but not for building a product.
Phase 2: Structured manual testing. With a deadline to launch alongside GPT-4's public announcement in March 2023, they built an internal prompt playground for more repeatable testing. Faster than Slack, but still relied on humans to read outputs and judge quality.
Phase 3: Automated post-hoc evals. This is where things got serious. They assembled a team of PhDs in education to define what good tutoring actually looks like, then had human raters apply that rubric to chat transcripts, targeting 85% inter-rater agreement. Once they had that ground-truth dataset, they used it to train an LLM-as-judge to label transcripts at scale. The key insight: many teams spin up LLM-as-judge systems with no ground truth, resulting in unreliable results. Khan Academy invested in the hard work of human annotation first. Once the machine matched human accuracy, they scaled it to process thousands of interactions nightly.
Phase 4: A/B testing in production. With reliable automated evals in place, they could finally run controlled experiments on prompt changes, system instructions, and even entire model swaps, all measured against metrics like cognitive engagement, item performance, undesirable tutoring behaviors (like giving away answers), and latency as a guardrail. This is the stage they're in now, with 64 completed experiments, 29 running, and 13 queued as of February 2026.
The takeaway: as AI products mature, your evaluation methods need to mature with them. You can't skip straight to production A/B testing without the foundation of knowing what "good" looks like.
The Math Agent Story: What Iterative AI Experimentation Actually Looks Like
Kelli shared a concrete example that perfectly illustrates how A/B testing enables teams to "hill climb" toward better AI quality. The problem: Khanmigo had a math agent, essentially a calculator it could call to verify computations. Great for accuracy, but it added latency that was painful in classroom settings.
Here's how the iterations played out:
Iteration 1: Remove the math agent entirely. Latency improved, but math errors doubled. Rolled back immediately.
Iteration 2: Switch to GPT-5. Latency decreased, but math accuracy still suffered. Rolled back.
Iteration 3: Optimize the math agent's prompts. They tightened the system instructions to be more efficient. Latency dropped by three seconds, and math accuracy held. A real win.
Iteration 4: Give the math agent a faster model. Reduced latency by another 300 milliseconds with stable accuracy.
Iteration 5: Time-box the math agent's execution. Further latency reduction, accuracy still stable.
Without A/B testing, the team might have shipped Iteration 1 or 2 and unknowingly degraded the learning experience. The experiments gave them the confidence to reject changes that looked good on one metric but failed on the one that mattered most. This is what "hill climbing" looks like in practice: hypothesis, test, measure, iterate. No single change was transformative. The cumulative effect was.
From Speed Bump to Safety Net: The Cultural Shift
Perhaps the most important takeaway from Kelli's talk was about culture. Before Khanmigo, experimentation at Khan Academy was seen as a speed bump. Product teams wanted to ship based on strong founder intuition and internal conviction. Running an A/B test felt like an obstacle to velocity.
Generative AI changed that completely. LLMs are unpredictable enough that even small changes to prompts or system instructions can produce dramatically different outputs. Teams quickly learned that shipping without testing was genuinely risky. The same engineers who once resisted experimentation now actively request it.
Experimentation went from being perceived as something that slows you down to being the safety net that gives teams the confidence to move fast. That cultural transformation, more than any individual experiment result, may be the most valuable outcome of Khan Academy's journey.
Want to hear the full story from Kelli? She'll be joining us for a live webinar on April 16, 2026, where she'll share this full story.


