

Background
With the advent of generative AI, companies across all industries are leveraging these models to enhance productivity and improve product usability.
At GrowthBook we have the unique opportunity to apply generative AI to the challenges of experimentation and A/B testing as an open-source company.
After careful consideration of the various applications of generative AI within the experimentation and A/B testing space, we decided to focus on creating an AI-powered hypothesis generator. This project not only allowed us to quickly prototype but also provided a rich roadmap for further innovation as we explore the potential of large language models (LLMs) in online controlled experiments.
An AI-powered hypothesis generator
Problem: New users often struggle to identify opportunities for optimizing their websites, while experienced users may need fresh ideas for new experiments.
Solution: Our AI-powered hypothesis generator analyzes websites and suggests actionable changes to achieve desired outcomes. It can generate DOM mutations in JSON format, making it easier to create new experiments in GrowthBook. For example, on an e-commerce site, the generator might recommend repositioning the checkout button or simplifying the navigation menu to boost conversion rates.
Overview
In our first iteration of the AI-powered hypothesis generator, we focused on a straightforward approach using existing technology. Below, we outline our process, the challenges we encountered, and how we plan to improve in future iterations.
Hypothesis generation steps
To accomplish the task of generating hypotheses for a given web page, there were a few discrete steps that the application would need to accomplish:
- Analyze the web page by scraping its contents.
- Prompt an LLM for hypotheses using the scraped data and additional context.
- If feasible, prompt the LLM to generate DOM mutations in a format compatible with our Visual Editor.
- Onboard the generated hypothesis and visual changes into GrowthBook.
Hypothesis generator tech stack
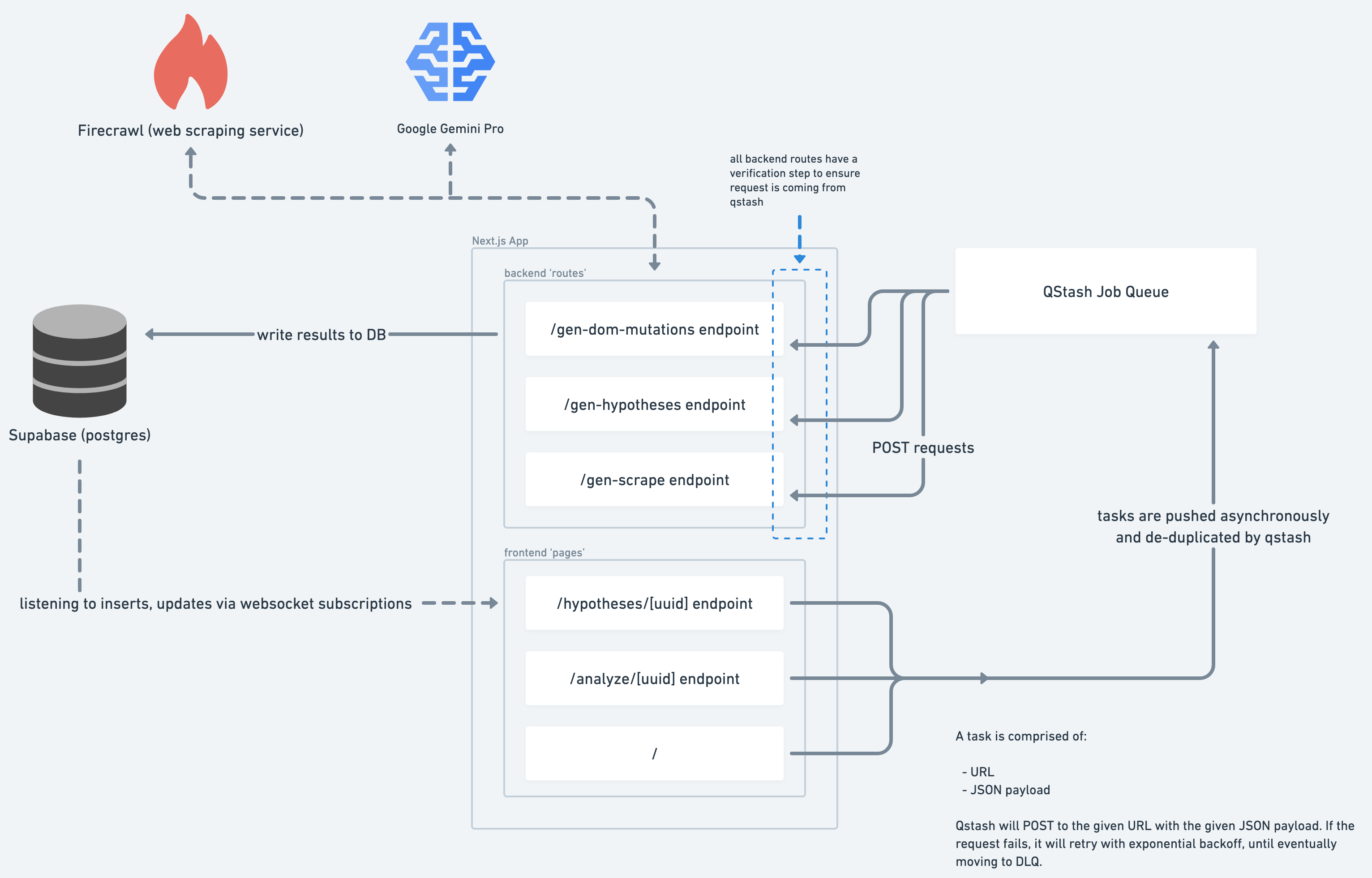
The hypothesis generator is built on a Next.js App supported by several services:
- Web scraping - Firecrawl
- Hypothesis generation via LLM - Google Gemini Pro
- Background async job system - Upstash QStash
- Backend data storage - Supabase (Postgres)
System Architecture for WebLens
Scraping the page
To provide the LLM with the context it needs to form hypotheses, we needed a way to serialize a web page into data that it could understand, that is: text and images.
We were lucky to partner with another YC company, Firecrawl for web scraping. Initially, we used Playwright, but switched to Firecrawl for its simpler API and reduced resource utilization.
Firecrawl helps us:
- Provide a markdown-representation of the page’s contents
- Deliver the full, raw HTML of the page.
- Capture a screenshot of the page.
Prompting the LLM
Now for fun part - we had to learn how to prompt the LLM to get accurate and novel results. There were a number of challenges that arose in this area of the project.
In the beginning, we experimented with OpenAI GPT 4, Anthropic Claude 2.1, and Google Gemini Pro. We also made sure to acquaint ourselves with established prompting techniques and leveraged those that seemed to improve results.
In the end we decided to go with Google Gemini Pro chiefly for its large context window of 1 million tokens. The difference in quality of hypotheses was negligible but we thought OpenAI’s GPT-4 did slightly better.
Prompt engineering
We experimented with a variety of novel prompting techniques (as well as a bit of sorcery and positive thinking) in order to output hypotheses of suitable quality. Here are a few of the techniques that we found useful:
- Multi-shot prompting: We combed through examples of successful A/B tests targeting different disciplines and segments of a website (ex: changing CTA UI and colors, altering headlines for impact, implementing widgets for user engagement, etc.) and reduced them to discrete test archetypes, which we fed into the prompt context. We also gave examples of failed A/B tests, as well as types of hypotheses that wouldn’t easily translate to good tests. This helped tighten up the variety of hypotheses produced as well as subjectively improved the quality of hypotheses.
- Contextual priming: We extended our multi-shot context-building strategy to include priming. Specifically, we included phrases in our prompts such as ”You are a UX designer who is tasked with creating hypotheses for controlled online experiments…” or ”Try to focus on hypotheses that will increase user engagement.” We also found it helpful to break down hypothesis generation task into steps and to provide details on how to conduct those steps.
- Ranking and validation: We asked the model to rank its output on various numerical and boolean scores (quality, ease of implementation, impact, whether or not there was an editable DOM element on the page, etc). This allowed us to rank and filter hypotheses, ensuring a good mixture of small, medium, and moon-shot ideas, as well as those which would translate well to a visual experiment.
Context window limits
Context window limits quickly became a challenge when trying to provide full web page scrape data to the LLM. This was a hard problem to compromise - there was no way around providing the full payload of scrape data. For example, it could be possible that crucial <style> tags were included near the bottom of the page. In general, there could be important details anywhere throughout the DOM that could affect the LLMs ability to formulate reliable hypotheses.
We came up with ideas on how to approach this problem in the long-term, but for now, we decided to take advantage of Google Gemini’s large context window to allow us to provide a nearly-full scrape of a webpage (with irrelevant markup removed) and still have enough token space left over for our prompt and the resultant hypotheses.
Generating DOM mutations
To take things one step further, we wanted to add the ability to use a generated hypothesis to prompt the LLM to generate DOM Mutations in a JSON format used by our Visual Editor. These mutations could then be used to render live previews in the browser.
We encountered some amazing results along with some pretty disastrous ones while experimenting with this. In the end, we had to narrow the focus of our prompt to focus only on modifying the text copy of very specific elements on a page, so that the live previews were reliably good. We also implemented iterative prompting to ensure the generated mutations were usable, testing them out on a virtual DOM and suggesting fixes to the LLM when possible.
Future iterations could improve accuracy and power by refining this process.
Scalability
To ensure reliability and support increased traffic from platforms like Product Hunt and Hacker News, we used Upstash’s QStash for a message queue. This system provides features like payload deduplication, retrying with exponential backoff, and a DLQ.
On the frontend, we used Supabase’s Realtime feature to notify clients immediately when steps are completed.
Challenges
Context window limits
One of the major challenges we faced was dealing with context window limits. Scraped HTML pages can range from 100k to 300k tokens, while most models' context windows are under 100k, with Google Gemini Pro being an exception at 1 million tokens. While large context windows simplify the developer experience by allowing us to create a single, comprehensive prompt for inference, they also come with the risk of the model focusing on irrelevant details.
Long context windows offer both advantages and disadvantages. On the plus side, they make it easier for developers by accommodating all necessary data in one prompt. This is particularly useful for use cases like ours, where raw HTML doesn't align well with techniques like Resource Augmented Generation (RAG). However, larger prompts can lead to unexpected inferences or hallucinations by the model.
Despite these challenges, our tests showed that Gemini Pro consistently produced relevant and innovative hypotheses from the scraped data. Looking ahead, we plan to enhance this process by using machine learning to categorize web pages and break them down into common UI groupings, such as "hero section" or "checkout CTA" for e-commerce sites.
By creating a taxonomy of web pages, we can use machine learning to extract essential details from each UI grouping, including screen captures and raw HTML. This approach reduces the amount of HTML from 300k+ tokens to less than 10k per grouping. Such optimization will enable faster, more accurate, and higher-quality inference across a broader range of models, even those with smaller context window limits.
Naming
We had a tough time coming up with a name for the tool - at one point considering “Lenticular Labs.” We ultimately chose WebLens to emphasize the tool's ability to analyze websites through a lens, enhancing focus. Plus, we secured the domain weblens.ai.
Conclusion
We hope you enjoyed reading this high-level overview of how we came to build the hypothesis generator at GrowthBook. Our current implementation is straightforward and utilizes tools that are readily available today, yet is able to generate novel insights given any web page on the internet today. Give it a shot with your website of choice at https://weblens.ai and let us know your thoughts via our community slack.



