

Bandits have been released in beta as part of GrowthBook 3.3 for Pro and Enterprise customers. See our documentation on getting started with bandits.
Multi-armed bandits allow you to test many variations against one another, automatically driving more traffic towards better arms, and potentially discovering the best variation more quickly.
Bandits are built on the idea that we can simultaneously…
- … explore different variations by randomly allocating traffic to different arms; and
- … exploit the best performing variations by sending more and more traffic to winning arms.
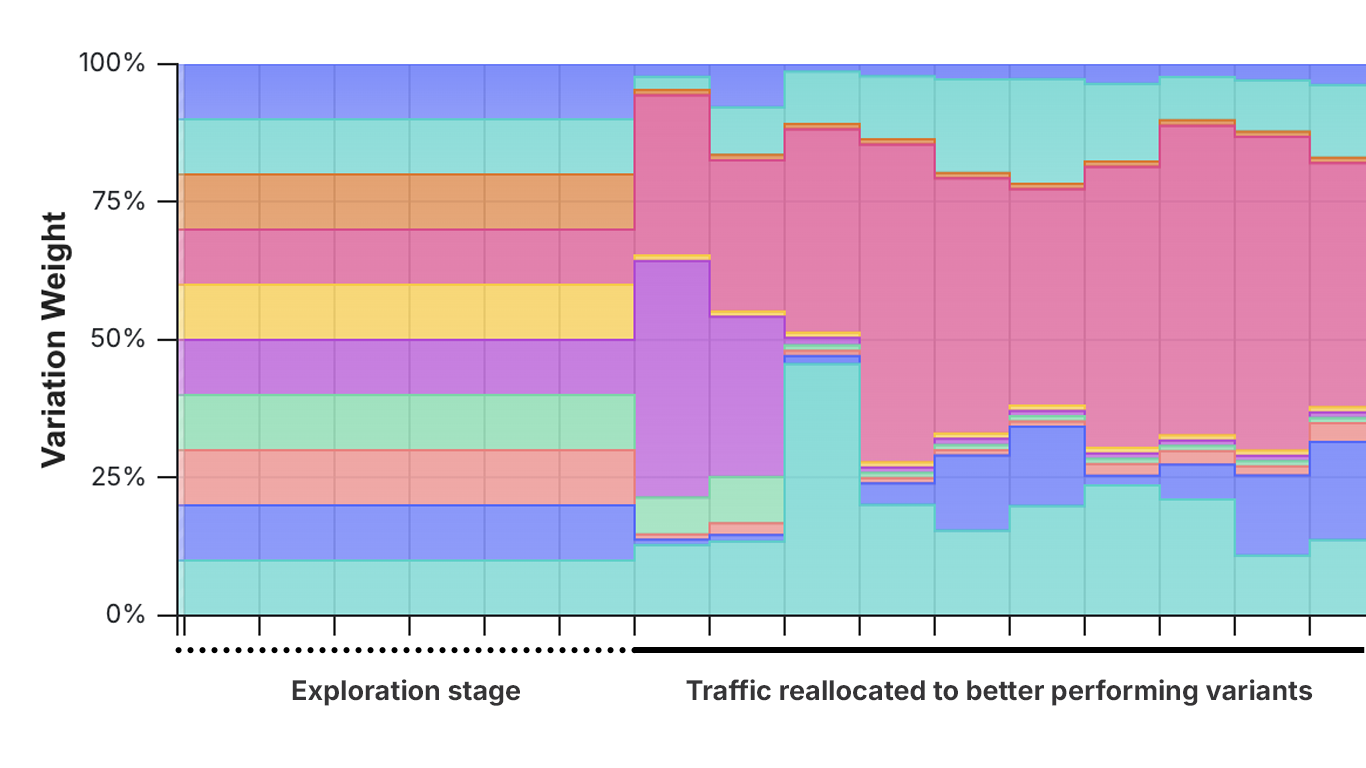
In online experimentation, bandits can be particularly useful if you have more than 4 variations you want to test against one another. Scenarios where bandits can be helpful include:
- You are running a short-term promotional campaign, and want to begin driving traffic to better variations as soon as there is any signal about which variation is best.
- You have many potential designs for a call-to-action button for a user sign-up, and you care more about just picking the best flow that leads to sign-up.
Furthermore, bandits work best when:
- Reducing the cost of experimentation is paramount. This is true in cases like week-long promotions where you don’t have time to test 8 versions of a promotion and then launch it, so you want to test 8 versions of a promotion and begin optimizing after just a few hours or the first day.
- You have a clear decision metric that is relatively stable. Ideally, your decision metric should not be an extreme conversion rate metric (e.g. < 5% or > 95%), or if it’s a revenue metric, you should apply capping to prevent outliers from adding too much variance.
- You have many arms you want to test against one another, and care less about learning about user behavior on several metrics than about finding a winner.
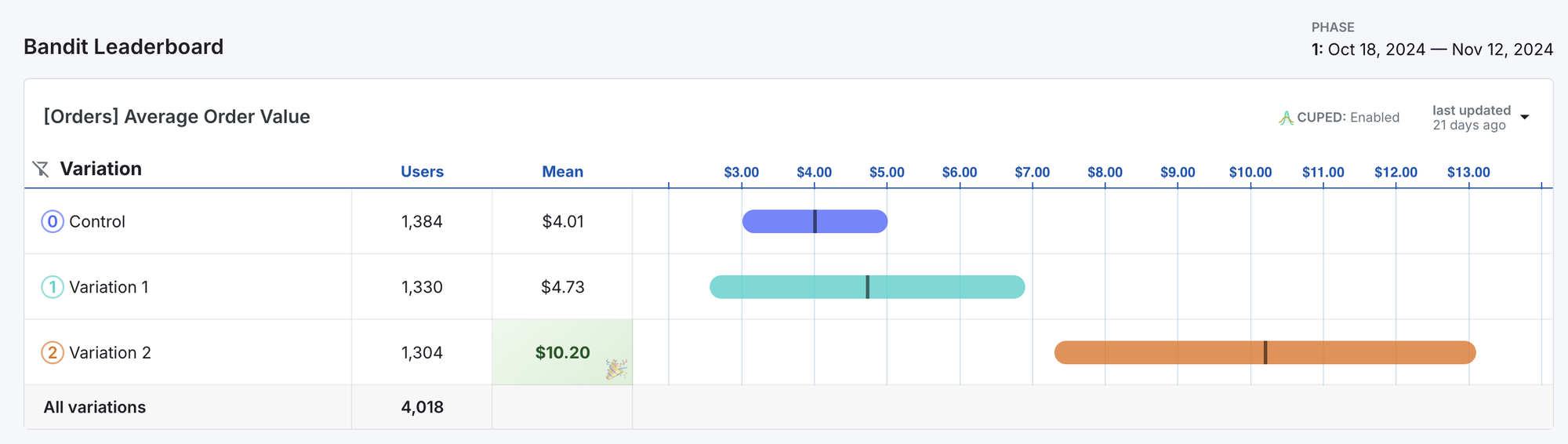
Read more about when and how to use bandits in our documentation.
The following table provides an summary of the differences between bandits and standard experiments.
| Characteristic | Standard Experiments | Bandits |
|---|---|---|
| Goal | Obtaining accurate effects and learning about customer behavior | Reducing cost of experimentation when learning is less important than just shipping the best version |
| Number of Variations | Best for 2-4 | Best for 5+ |
| Multiple goal metrics | Yes | No |
| Changing Variation Weights | No | Yes |
| Consistent User Assignment | Yes | Yes (with Sticky Bucketing) |
What makes GrowthBook’s bandits special?
GrowthBook's bandits rely on Thompson Sampling, a widely used algorithm to balance exploring the value of all variations while driving most traffic to the better performers. However, our bandits are different in a few ways that ensure it works well in the context of digital experimentation.
Consistent user experience
Some bandit implementations do not preserve user experience across sessions, making those bandits tricky to use when stable user experiences are important. Because bandits dynamically update the percent of traffic going to each variation, if you run it on users who return to your site or your product and do not preserve their user experience, they may be exposed to a number of different variations over the course of one bandit.
This can lead to:
- Bad user experiences where your product frequently changes for an individual customer.
- Biased results.
GrowthBook uses Sticky Bucketing, a service that allows you to store user variations in some service, such as a cookie, so that when they return they always get the same experience, even when the bandit has updated variation weights.
Setting up Sticky Bucketing in our HTML SDK is as easy as adding a parameter to our script tag.
<script async
data-client-key="CLIENT_KEY"
src="<https://cdn.jsdelivr.net/npm/@growthbook/growthbook/dist/bundles/auto.min.js>"
data-use-sticky-bucket-service="cookie"
></script>Implementing Multi-Armed Bandits in GrowthBook
Accommodates changing user behavior
GrowthBook’s bandits use a weighting method to prevent changing user behavior over time from biasing your results.
What is the issue? As your bandit runs, two things are changing: your bandit updates traffic allocations to your variations, and the kind of user entering your experiment changes (e.g., due to day-of-the-week effects). The correlation between these two can cause biased results if not addressed.
Imagine the following scenario:
You run a bandit that updates daily. You start your bandit on Friday and you have two variations that have a 50/50 split (100 observations per arm). You observe a 45% conversion rate in Variation A, and a 50% conversion rate in Variation B. After the first bandit update, the weights become 10/90 (just as an illustration, the actual values would be different). The total traffic on Saturday is also 200 users, but this time Variation B gets 90% of the traffic. Conversion rates on weekdays tend to be higher than on weekends, regardless of variation. On Saturday, you observe a 10% conversion rate in Variation A and a 15% conversion rate in Variation 2. On both Friday and Saturday, Variation B has larger conversion rates, but if you naively combine the data across both days, Variation A looks like the winner:
| Friday | Saturday | Combined | |
|---|---|---|---|
| Variation A | 45 / 100 = 45% | 2 / 20 = 10% | 47 / 120 = 39% |
| Variation B | 50 / 100 = 50% | 27 / 180 = 15% | 77 / 280 = 27.5% |
The combined conversion rate for Variation B is 27.5%, while for Variation A it is 39%, despite Variation B outperforming Variation A on both days of the experiment. Clearly something is wrong here. In fact, sharp eyed readers might notice this is a case of Simpson’s Paradox.
How did we solve it? We use weights to estimate the mean conversion rate for each bandit arm under the scenario that equal experimental traffic was assigned to each arm throughout the experiment. In this scenario, we can recompute the observed conversion rates as if the arms received equal traffic (e.g., on Saturday we had 10/100 conversions instead of 2/20). Using these adjusted conversion rates, the combined conversion rates now make sense:
| Friday | Saturday | Combined | |
|---|---|---|---|
| Variation A | 45/100 = 45% | 10/100 = 10% | 55/200 = 27.5% |
| Variation B | 50/100 = 50% | 15/100 = 15% | 65/200 = 32.5% |
Variation B is now the winner. By accounting for the changes in overall traffic on each day, the combined conversion rate now appropriately accounts for the differences in conversion rates and variation traffic over time. Our bandit applies a similar logic to ensure that day-of-the-week effects and other temporal differences do not bias your bandit results.
Built on a leading warehouse-native experimentation platform
GrowthBook is the leading open-core experimentation platform. It is designed to live on top of your existing data infrastructure, adding value to your tech stack without complicating it.
GrowthBook integrates with BigQuery (GA4), Snowflake, Databricks, and many more data warehouse solutions. If your events land within minutes in your data warehouse, then GrowthBook bandits can adaptively allocate traffic within hours or less.
Get started
To get started with Bandits in GrowthBook, check out our bandits set-up guide, or if you’re new to GrowthBook, get started for free.


