

We are excited to announce the release of GrowthBook version 0.8.0 which includes some large improvements and features:
All new design!
The design of GrowthBook got an overhaul from top to bottom, with new navigation, colors, and layout to improve the user experience. Try it out on our cloud version.
Up to 10x faster statistical analyses
We greatly reduced the number of roundtrips between our Typescript API and Python statistics engine and optimized the data processing steps. This resulted in a huge performance gain, especially noticeable on experiments with many metrics or a high-cardinality dimension selected. We’ve seen some analyses go from 50+ seconds of processing time down to under 5 seconds.
Dimensional Analysis Improvements
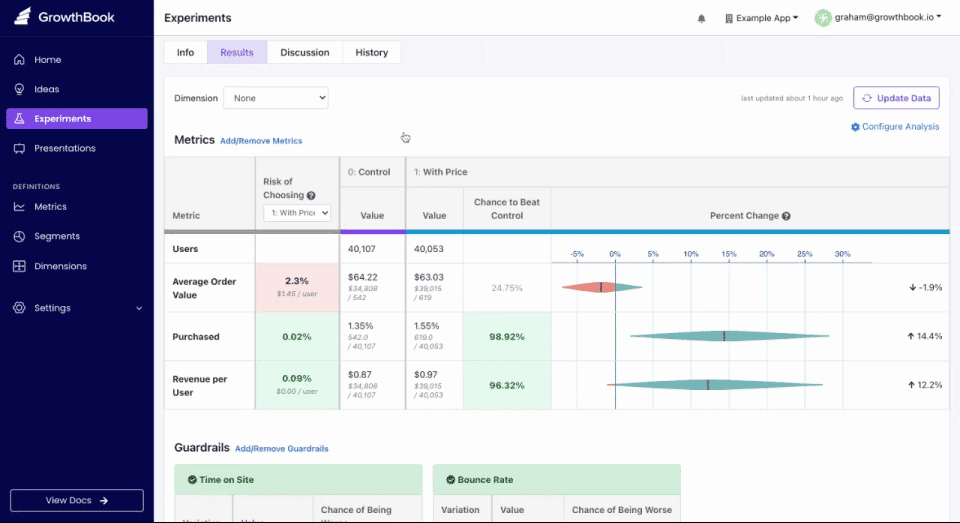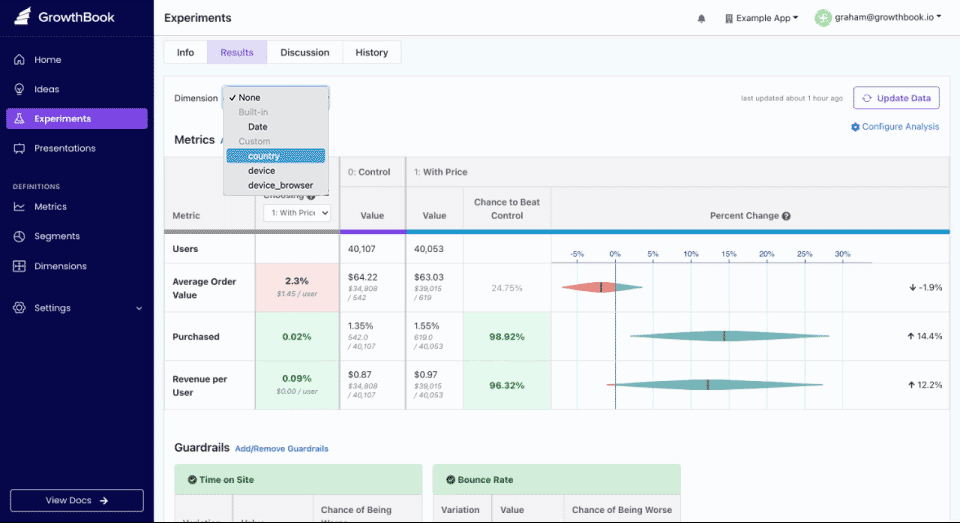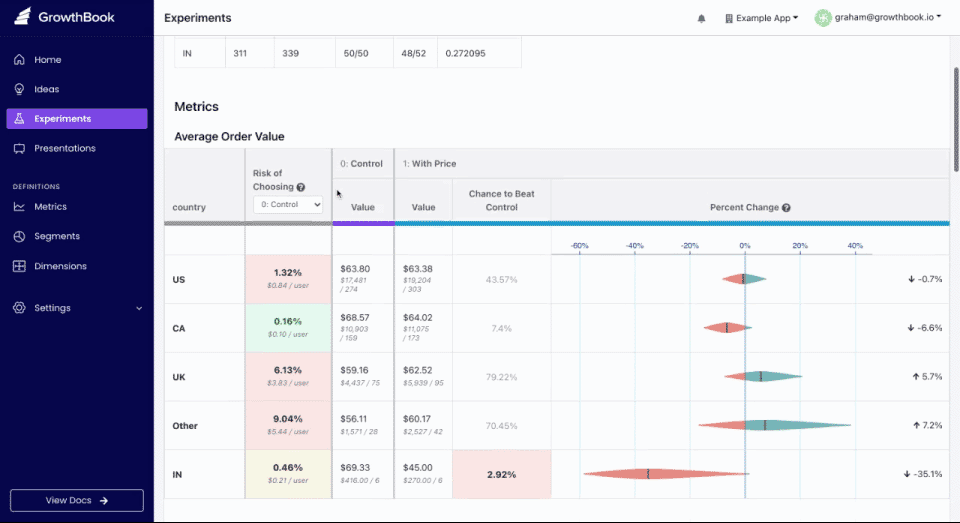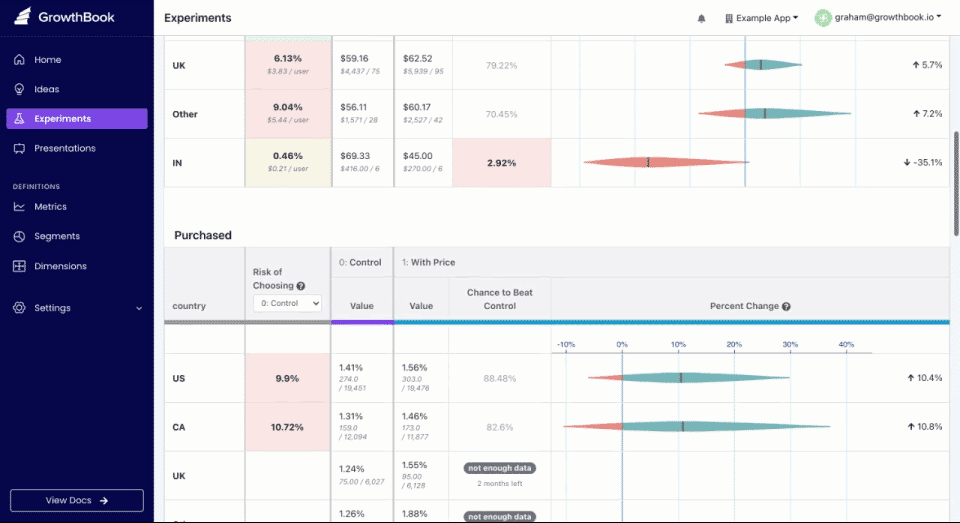
We launched several new improvements to the dimensional analysis features of our experiment results:
Automatic dimensionality reduction
If you have a dimension with high cardinality (e.g. a “country” dimension with 200 possible values), GrowthBook now automatically groups values to reduce the number of statistical analyses that are performed. It will leave the top 20 values (by number of users) as-is so you can still draw useful inferences, but will group everything else into “(other)”. This reduces the chance of seeing a false positive and makes the report easier to read.
Jupyter notebooks of dimensional breakdowns
We reworked and improved our popular Jupyter Notebook Export feature. Now you can export any experiment results page as a notebook, including dimension breakdowns. Plus, we’ve added many new columns to our Pandas dataframes to give you maximum flexibility when playing around with the data. Make sure to install the latest version of gbstats (0.2.0) from PyPi to support this new notebook format.
Mutually exclusive experiment support
As you scale up experimentation at your company, you will inevitably run into situations where you want to run two conflicting experiments at the same time. With the introduction of namespaces in our JS and React SDKs (others coming soon!), you can now safely achieve this. Namespaces work by splitting users into 1000 buckets and letting you specify the bucket range each experiment within that namespace should apply to. As long as the bucket ranges of two experiments don’t overlap, they will be mutually exclusive. You can segment your product into as many namespaces as you want and greatly improve your test velocity!
Plus numerous other enhancements and bug fixes. You can read about the full list of changes here.



