

Quick Takeaways
- Performance varies by domain: Models that ace benchmarks often fail on your specific use case
- The Trade-offs might not be real: Faster, cheaper models might outperform expensive ones for your needs
- The best solution is rarely one model: Most successful deployments use model portfolios
A/B testing quantifies what matters: User completion rates, costs, and latency—not abstract scores
Introduction
OpenAI's GPT-5 (high) model scores 25% on the FrontierMath benchmark for expert-level mathematics. Claude Opus 4.1 only scores 7%. Based on these numbers alone, you might assume GPT-5 is clearly the superior choice for any application requiring mathematical reasoning.
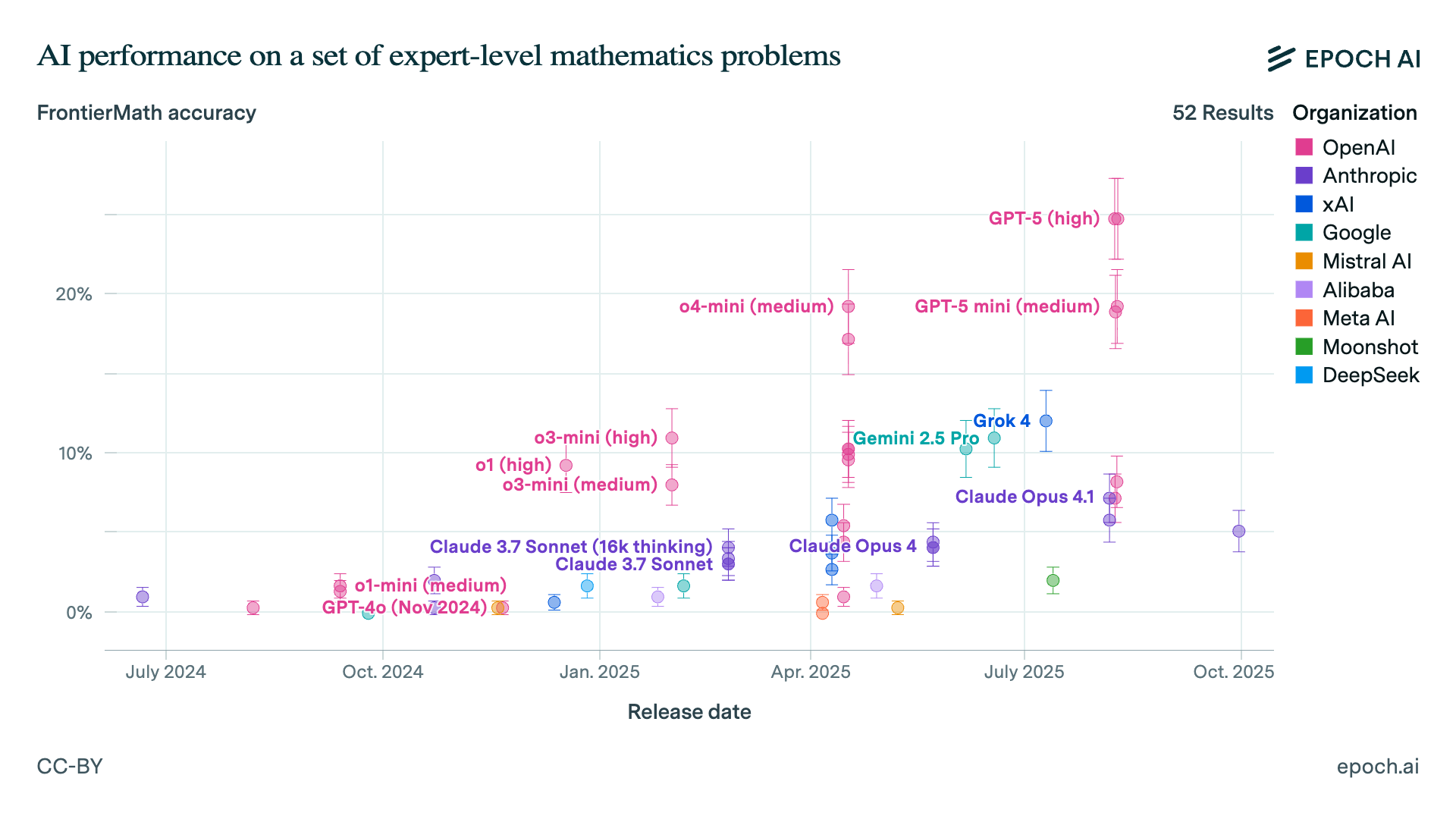
But this assumption illustrates a fundamental problem in AI evaluation, one that we in the experimentation space know quite well as Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure." The AI industry has turned benchmarks into targets, and now those benchmarks are failing us.
When GPT-4 launched, it dominated every benchmark. Yet within weeks, engineering teams discovered that smaller, "inferior" models often outperformed it on specific production tasks—at a fraction of the cost.
With all the fanfare of the GPT-5 launch and outperforming all other models on coding benchmarks, developers continued to prefer Anthropic's models and tooling for real-world usage. This disconnect between benchmark performance and production reality isn't an edge case. It's the norm.
The market for LLMs is expanding rapidly—OpenAI, Anthropic, Google, Mistral, Meta, xAI and dozens of open-source options all compete for your attention. But the question isn't which model scores highest on benchmarks. It's which model actually works in your production environment, with your users, under your constraints.
Why Traditional Benchmarks Fail in Production
AI benchmarks are standardized tests designed to measure model performance—MMLU tests general knowledge, HumanEval measures coding ability, and FrontierMath evaluates mathematical reasoning. Every major model release leads with these scores.
But these benchmarks fail in three critical ways that make them unreliable for production decisions:
1. They Don't Measure What Actually Matters Benchmarks test surrogate tasks—simplified proxies that are easier to measure than actual performance. A model might excel at multiple-choice medical questions while failing to parse your actual clinical notes. It might ace standardized coding challenges while struggling with your company's specific codebase patterns. The benchmarks measure something, just not real-world problem-solving ability.
2. They're Systematically Gamed Data contamination lets models memorize benchmark datasets during training, achieving perfect scores on familiar questions while failing on slight variations. Worse, models are specifically optimized to excel at benchmark tasks—essentially teaching to the test. When your model has seen the answers beforehand, the test becomes meaningless.
3. They Ignore Production Reality Benchmarks operate in a fantasy world without your constraints. Latency doesn't exist in benchmarks, but your multi-model chain takes 15+ seconds. Cost doesn't matter in benchmarks, but 10x price differences destroy unit economics. Your infrastructure has real memory limits. Your healthcare app can't hallucinate drug dosages.
Consider this sobering statistic: 79% of ML papers claiming breakthrough performance used weak baselines to make their results look better. When researchers reran these comparisons fairly, the advantages often disappeared.
The A/B Testing Advantage: Finding What Actually Works
So if benchmarks fail us, how do we actually select and optimize LLMs? Through the same methodology that transformed digital products: rigorous A/B testing with real users and real workloads.
The Portfolio Approach
The first insight from production A/B testing contradicts everything vendors tell you: the optimal solution is rarely a single model.
Successful deployments use a portfolio approach. Through testing, teams discover patterns like:
- Simple queries handled by models that are fast, cheap, and good enough
- Complex reasoning routed to thinking models
- Domain-specific tasks sent to fine-tuned specialist models
Take v0, Vercel's AI app builder. It uses a composite model architecture: a state-of-the-art model for new generations, a Quick Edit model for small changes, and an AutoFix model that checks outputs for errors.
This dynamic selection approach can slash costs by 80% while maintaining or improving quality. But you'll only discover your optimal routing strategy through systematic testing.
Metrics That Actually Drive Business Value
Production A/B testing reveals the metrics that benchmarks completely miss:
Performance Metrics That Matter:
- Task completion rate: Do users actually accomplish their goals?
- Problem resolution rate: Are issues solved, or do users return?
- Regeneration requests: How often is the first answer insufficient?
- Session depth: Are simple tasks requiring multiple interactions?
Cost and Efficiency Reality:
- Tokens per request: Your actual API costs, not theoretical pricing
- P95 latency: How long your slowest users wait (the ones most likely to churn)
- Throughput limits: Can you handle Black Friday or just Tuesday afternoon?
Counterintuitive insight: If an LLM solves a user's question on the first try, you may see fewer follow-up prompts. That drop in "requests per session" is actually positive—your model is more effective, not less engaging.
Making A/B Testing Work for LLMs
Testing LLMs requires adapting traditional experimental methods to handle their unique characteristics:
Handle the Randomness: Unlike deterministic code, LLMs produce different outputs for the same prompt. This variance means:
- Run tests longer than typical UI experiments
- Use larger sample sizes to achieve statistical significance
- Consider lowering temperature settings if consistency matters more than creativity
Isolate Your Variables: Test one change at a time:
- Model swap (GPT-5 → Claude Opus)
- Prompt refinement (shorter, more specific instructions)
- Parameter tuning (temperature, max tokens)
- Routing logic (which queries go to which model)
Without this discipline, you can't attribute improvements to specific changes.
Set Smart Guardrails: Layer guardrail metrics alongside your primary success metrics. An improvement in task completion that doubles costs might not be worth deploying. Track:
- Cost per successful interaction (not just cost per request)
- Safety violations that could trigger PR nightmares
- Latency thresholds that cause user abandonment
Build Once, Test Forever: Invest in infrastructure that makes testing sustainable:
- Centralized proxy service for LLM communications
- Automatic metric collection and monitoring
- Prompt versioning and management
- Response validation and safety checking
This investment pays off immediately—making tests easier to run and results more trustworthy.
Embrace Empiricism
Benchmarks aren't entirely useless—use them for initial screening, understanding capability boundaries, and meeting regulatory minimums. But they should never be your final decision criterion.
The AI industry's benchmark obsession has created a dangerous illusion. Models that dominate standardized tests struggle with real tasks. The metrics we celebrate have divorced from the outcomes we need.
For teams building with LLMs, the path is clear:
- Start with hypotheses, not benchmarks: "We believe Model X will improve task completion" not "Model X scores higher"
- Test with real users and real data: Your production environment is the only benchmark that matters
- Measure what moves your business: User satisfaction, cost per outcome, and regulatory compliance
- Iterate based on evidence: Let data, not vendor claims, drive your model selection
The benchmarks aren't exactly lying—they're just answering the wrong questions. A/B testing asks the right ones: Will this solve my users' problems? Can we afford it at scale? Does it meet our requirements?
In the end, the best benchmark for your AI isn't a standardized test. It's users voting with their actions, costs staying within budget, and your application delivering real value.
Everything else is just numbers on a leaderboard.


