

It’s Friday, quarter to 5:00 PM. Your team deploys a major checkout redesign to production. Within minutes, its error rates start spiking.
Your Slack’s on fire and your CEO is asking a ton of questions. Next thing you know, you’re staring down a long night of reverting commits and explaining what happened.
Now imagine the same scenario with one change. You disable the feature in 10 seconds with a single click, without redeploying code.
That’s the difference between deploying code and deploying code behind a feature flag.
In this guide, we’ll cover what feature flags are and how product and engineering teams can use them successfully.
What Are Feature Flags?
A feature flag is a conditional mechanism in your code that lets you toggle application behavior at runtime, without deploying new code.
You wrap a feature in a flag, deploy it in an “off” state, and turn it on when you’re ready. If something goes wrong, you turn it off, which rolls back the deployed feature.
Feature flags are also referred to as feature toggles or feature switches, but they all describe the same mechanism. At their simplest, feature flags are if/else blocks that check a configuration value to decide which code path runs:
const newCheckout = useFeatureIsOn(“new-checkout”)
if (newCheckout) {
return <NewCheckoutFlow />;
} else {
return <LegacyCheckout />;
}You deploy this code with the feature turned off. So, everyone sees the legacy checkout. When you’re ready, you flip the flag to deploy the feature and flip it back off again if something goes wrong or you’re done testing it.
How Do Feature Flags Work?
Feature flag systems have three main components that work together to give you complete control over your features:

1. Flag Configuration
Flag configuration is where you define your flags and the rules that govern them. That can be as simple as a config file or as sophisticated as a dedicated feature management platform with a user interface (UI), audit logs, and role-based access.
Here’s an example configuration for a new-checkout flag:
{
“new-checkout”: {
“defaultValue“: false,
“rules“: [
{
“condition”: {
“beta“: true
},
“force”: true // Forces the flag ON when condition matches
}
]
}
}
This config enables the new checkout only for beta testers, so you can test the new flow with a small set of users before rolling out the final version.
Note: If you’re wondering why you can’t set environment variables for this, it’s because those variables require redeployment to change. Flags don’t.
2. Flag Delivery
Once you’ve defined your flags, the configuration needs to reach your application. This can be through an included file at build time, API calls, streaming updates, or a mix of all three.
The method you choose decides how fast the changes propagate. That’s why platforms like GrowthBook deliver via server-sent events (SSE) to push changes immediately. The changes come through within milliseconds.
3. Flag Evaluation
The final component is where your application actually resolves a flag’s value. The SDK (or your custom code) takes the user’s attributes and evaluates them against the flag’s rules. Based on that, the SDK returns the appropriate value.
// Beta user
const gb = new GrowthBook({
attributes: { id: “user_123”, beta: true }
});
gb.isOn(“new-checkout”) // Returns: true
// Regular user
const gb = new GrowthBook({
attributes: { id: “user_456”, beta: false }
});
gb.isOn(“new-checkout”) // Returns: false (uses defaultValue)
In this example, the beta user’s attributes match the rule. So, the flag evaluates to true, and the new checkout renders. If it doesn’t, the flag falls back to the default value of false.
Note: When a flag is disabled (not just set to false, but turned off entirely), most platforms—including GrowthBook—evaluate it as null rather than false. Here, the fallback value will be used if you’ve added one. The boolean one won’t give you an error, it’ll render as false.
What Are the Types of Feature Flags?
All feature flags don’t serve the same purpose. And they aren’t meant to live for the same period either.
We can categorize feature flags across three axes:
Here are the types of feature flags:
| Feature Flag Type | Lifespan | Primary purpose | Value type | Scope | Retirement |
|---|---|---|---|---|---|
| Deployment | 2–4 weeks | Testing and debugging code | Boolean | System-level | Yes, after testing code |
| Release | 2–8 weeks | Progressive rollout of new features | Boolean | User-level | Yes, always |
| Experiment | 2–6 weeks | A/B/n testing and variation assignment | String or JSON | User-level | Yes, after shipping the winner |
| Ops / Kill Switch | Long-lived | Emergency control, runtime config | Boolean or number | System or user-level | No, adjust as needed |
| Permission | Permanent | Access control by tier, role or geography | Boolean | User-level | No, part of business logic |
By Time Span
There are two types of feature flags based on when or if you retire them:
- Short-lived flags: These toggles exist for days to weeks. You create them for a specific purpose—for instance, to ship a feature or run a test, and then remove them when you’re done. These flags are often the source of technical debt because people tend to forget to clean them up.
- Long-lived flags: These flags live in your codebase for months or permanently. They’re part of your app’s ongoing behavior. For example, you might need a kill switch to turn off a part of the app or an entitlement flag to control which users see certain features.
By Purpose
Feature flags can be classified into five types based on usage:
1. Release Flags
You can use release flags to control the rollout of new features during the release process.
if (gb.isOn(“new-checkout-flow”)) {
return <NewCheckoutFlow />;
}
return <LegacyCheckout />;A typical lifecycle looks like this:
- Create the flag
- Test with internal users
- Run a progressive rollout (5%, 25%, 50%, 100%)
- Confirm everything is stable
- Remove the flag and the old code path entirely
Most release flags should live for 2 to 8 weeks. If yours has been around longer, it’s time to clean up. Platforms like GrowthBook include stale feature flag detection to surface flags that haven't been evaluated recently, so you know which ones are overdue for cleanup.
2. Experiment Flags
You should use experiment flags to assign users to variations for A/B testing. The main difference is that consistent assignment matters because the same user should always see the same variation for both UX consistency and accurate measurement. Platforms like GrowthBook handle this automatically by hashing the user's ID, so assignment is stable without any extra work on your end.
For A/B testing, it’s also very important to ensure that users are randomly being assigned to both the control and variant groups.
const variant = gb.getFeatureValue(“checkout-cta-experiment”, “control”);
// Returns “control”, “variation_a”, or “variation_b”
switch (variant) {
case “variation_a”:
return <Button>Complete Purchase</Button>;
case “variation_b”:
return <Button>Place Order</Button>;
default: // control
return <Button>Buy Now</Button>;
}Typically, you’ll leave these on for as long as your experiments run—usually 2 to 6 weeks. But it depends on your traffic volume and the level of statistical power required. Once you’ve shipped the winning variant, remove the flag.
3. Operational Flags
Operational flags control system behavior and provide emergency shutoffs. Think about cases like circuit breakers, graceful degradation under load, and runtime configuration changes that don’t warrant a full deployment.
if (gb.isOn(“enable-recommendation-engine”)) {
recommendations = await fetchRecommendations(userId);
}
const cacheTimeout = gb.getFeatureValue(“redis-cache-ttl”, 300);
const rateLimit = gb.getFeatureValue(“api-rate-limit”, 1000);These flags are mostly permanent in nature. You can trigger them manually during incidents or automatically through monitoring or feature flagging systems. A kill switch is an excellent example of such a flag.
4. Permission or Entitlement Flags
Permission flags control feature access based on subscription tier, user role, geography, or account status. These depend on the business logic and aren’t necessarily used for development or testing purposes.
// Flag targeting evaluates user’s plan attribute
if (gb.isOn(“advanced-analytics“)) {
return <AdvancedAnalyticsDashboard />;
}
return <BasicAnalytics />;A permission flag evaluates the user’s attributes (like their plan tier) to determine access, but your application database remains the source of truth for those attributes. It doesn’t mean that the flag stores data, it just evaluates conditions.
A warehouse-native platform like GrowthBook can evaluate these attributes directly from your existing data without requiring data duplication or schema changes. Your warehouse is already the source of truth for plan tiers and user roles so you don’t have to bring them into another platform again.
Tip: Always evaluate entitlement flags server-side using verified data. If you do this client-side, the user can inspect your flag configuration in the browser’s dev tools and potentially change it to bypass controls.
5. Development Flags
Development flags are usually used to turn a feature on or off to test and debug code. These are short-lived, and you should turn them off after completing the QA or testing process.
By Scope
Depending on the scope, you can categorize it into two types:
- System-level flags: These flags affect your entire application uniformly. A kill switch that disables a service for all users, or a config flag that changes your cache TTL globally. These don’t care who the user is—they’re binary for the whole system.
- User-level flags: These flags evaluate differently per user based on their attributes—for example, user ID, plan tier, geography, device type, or behavioral signals. User-level flags are used in targeting, rollout, and experimentation because these are based on user attributes. Let’s say you’re launching a 10% rollout, you’re hashing user IDs to consistently assign each person to a cohort.
By Value Type
Value types describe what a flag returns. Most flags start as simple booleans, but as your use cases mature, you'll reach for more advanced types, such as:
- Boolean flags: These flags return true or false. This is the default for most feature flags, such as on/off toggles and kill switches. If you’re wrapping a feature in a flag for the first time, this is where you start.
- String flags: These flags return a text value. Use these when you need to serve different variations of content like button text in an A/B test ("Buy Now" vs. "Add to Cart"), or a theme identifier ("dark" vs. "light").
- Number flags: These flags return a numeric value. They’re useful for tuning runtime parameters such as cache TTLs, rate limits, pagination sizes, and retry counts without redeploying.
- JSON flags: These flags return structured data. A single JSON flag can control an entire component's behavior. For instance, returning { "layout": "grid", "rows": 10, "showFilters": true } to configure a UI layout without deploying new code. They’re also useful for complex experiment variations where each variant needs multiple parameters, or for configuration bundles that you want to manage as a single unit.
Who Uses Feature Flags and For What Purpose?
Even though feature flags started out as a developer practice, they’re no longer limited to the engineering team. If you implement them, even non-technical users can work with them.
Here’s how that works:
Technical Teams
- Developers and engineers: Development teams implement feature flags in code, manage rollouts, and use kill switches during incidents. The goal is to deploy with confidence by making every release reversible. They’re also responsible for maintaining and cleaning up unused or old flags.
- QA and testing: These teams use flags to validate features in production with real data, traffic patterns, and third-party integrations. Since staging environments can never fully replicate those conditions, feature flags allow them to get a sense of what will actually happen when the feature is live.
- DevOps and site reliability engineering (SRE): These teams rely on operational flags for circuit breakers, infrastructure migrations, and system configuration changes. For instance, if a service degrades, they can disable non-critical features to preserve core functionality.
- Data analysts: Analysts use flags to launch experiments, create targeting rules (who will be part of the experiment), and then randomly assign users to a variation. When a feature is launched as an experiment, analysts get clean and randomized data in their warehouse. For example, assignment records alongside behavioral events without having to add experimentation individually."
- Security and compliance: These teams audit flag changes to maintain a record of who released what, to whom, and when. Features like approval workflows and audit logs matter the most so that they can access that information. Also, if new regulatory requirements take effect, they can disable non-compliant features immediately.
Business and GTM Teams
- Product managers: Product teams use feature flags to control release timing and manage beta programs. Feature flags give product managers autonomy to ship code when the business is ready, not just when the code is. They also help data science teams with experimentation—for example, when they need to test how features perform with different audiences.
- Marketing: Typically, product marketing teams use flags to time feature releases to campaigns or run promotional experiments. Personalization is another key use case where they offer curated experiences based on audience (user attributes).
Note: While feature flags help non-technical users time feature releases, it doesn’t mean every feature flagging platform is intuitive enough to use. Consider using a platform like GrowthBook that lets non-technical team members create and manage feature flags without writing code or filing engineering tickets.
What Are the Benefits of Using Feature Flags?
Most product and engineering teams adopt feature flags to address a specific problem. Usually, it’s a painful deployment that went sideways. But there are several benefits of using feature flags, including:
Decouple Deployment from Release
Feature flags break the assumption that deploying code means releasing a feature. Your main branch can contain unreleased features safely wrapped in flags. And engineers can merge continuously without worrying about exposing incomplete work.
In short, your engineering team can deploy 10 times a day while releasing features weekly or whatever cadence the business needs.This is particularly beneficial when different teams are contributing to a feature. For example, if the back-end team delivers new functionality ahead of the front-end team, they check that code in behind a feature flag instead of keeping it in a branch.
Enable Instant Rollbacks
When things go wrong (and they will, usually at the worst possible time), you can disable a feature immediately. You don’t have to deploy new code or revert commits. As a result, you also recover from incidents much faster. Without a feature flag, engineering teams are often forced to create a new build that removes buggy code while keeping stable features that were included in the previous build. This can be a painful, time-consuming process, especially if the bug is hurting the live customer experience.
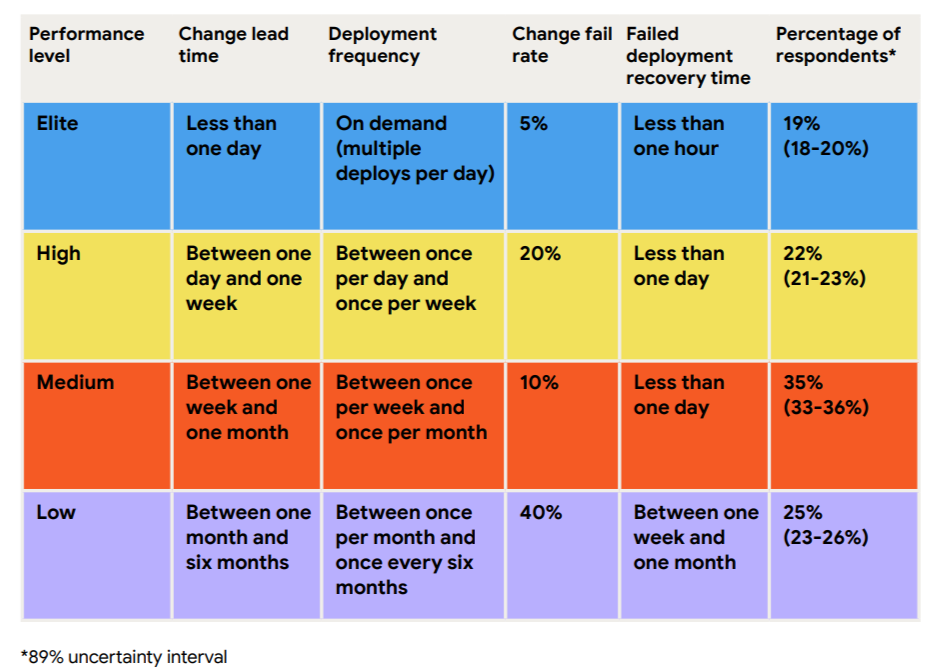
In fact, the State of DevOps 2024 report found that only 19% of engineering organizations recover from failed deployments in less than an hour. These “elite” teams tend to focus on continuous delivery practices, which are usually enabled by feature flags.
Reduce Risk with Progressive Rollouts
Instead of releasing to everyone at once, you can start small. First, roll out to 5% of users and monitor key metrics like error rates and performance. If everything looks good, gradually increase to 25%, then 50%, then 100%. If issues arise, the blast radius is limited to a small subset of users.
Test in Production Safely
Staging environments never perfectly mirror production. They lack real user behavior, real data volumes, and real traffic patterns, and you can’t make decisions if you’re testing in it.
For instance, if you’re testing a new payment processor integration, the staging environment can’t replicate the complexity of real payment flows or peak traffic loads. But if you use feature flags, you can test it with real user transactions, which gives you concrete data on what’s working (and not).
Increase Team Velocity
When you start using feature flags, velocity is a second-order benefit that you’ll experience eventually. Nobody’s waiting on shared release windows anymore, so they deploy code when it makes sense for them. So, teams ship faster and with more confidence in the long run.
In fact, according to research from DORA, higher deployment frequency correlates with higher software quality and stability. And it all comes down to feature flags that enable continuous delivery.
Enable Trunk-Based Development
Long-lived feature branches are a tax on your engineering team. They diverge from the main branch and accumulate merge conflicts over time, which causes more issues the longer they live.
That’s why sophisticated engineering teams have started adopting trunk-based development.
In this method, they merge incomplete code to main behind a flag where it’s deployed but never executed. So you get the benefit of continuous integration without the risk of shipping unfinished features to users.
Build a Foundation for Experimentation
Once you can control who sees what, the next question is: which version is actually better?
Feature flags give you the ability to test that. While they act as the delivery mechanism, experiments act as the measurement layer.
const variant = gb.getFeatureValue(“checkout-cta-text”, “Buy Now”);
// Returns: “Buy Now”, “Purchase”, or “Add to Cart”
// Assignment is stable per user for valid experiment resultsTogether, they move your team from “We shipped it and hope it works” to “We shipped it, measured it, and know it works.”
What Are the Use Cases of Feature Flags?
Here are the most common use cases of feature flags for product and engineering teams:
Release Management
You wrap a new feature in a flag, deploy it to production in an off-state, and progressively roll it out. You can use it for:
- Internal dogfooding with your team
- Beta access for a select group of users
- 5% canary release to catch issues early
- Gradual ramp to 25%, 50%, 100%
At each stage, you monitor metrics and can halt or roll back if problems appear. This transforms launches from high-stakes events into controlled, iterative processes.
Kill Switches and Operational Control
Sometimes the most important thing a feature flag does is turn something off. It’s usually used when incidents happen, and you need to respond quickly. This drastically reduces your mean time to recovery (MTTR).
Infrastructure Migrations
Big-bang deployments are becoming a thing of the past. You don’t need a whole ceremony to move from one database to another.
Let’s say you’re migrating from PostgreSQL to CockroachDB. All you have to do is route 1% of read queries to the new database and monitor its performance. If everything looks good, ramp up to 10% and so on and so forth until it’s complete.
A/B Testing and Experimentation
Feature flags are the natural foundation for experimentation. Once you can consistently assign users to different feature variations, you can measure which version performs better with statistical rigor.
This is becoming especially relevant for teams building AI and GenAI features. When your recommendation engine uses a large language model (LLM) or your search results rely on an embedding model, you can’t just eyeball whether the new version is better.
You need controlled experiments with guardrail metrics and feature flags that provide the infrastructure to run them in production safely.
Personalization and Targeting
Feature flags let you deliver different experiences based on user attributes, geography, device type, or behavioral signals. You don’t need to maintain separate codebases for each attribute because the targeting rules handle the variation.
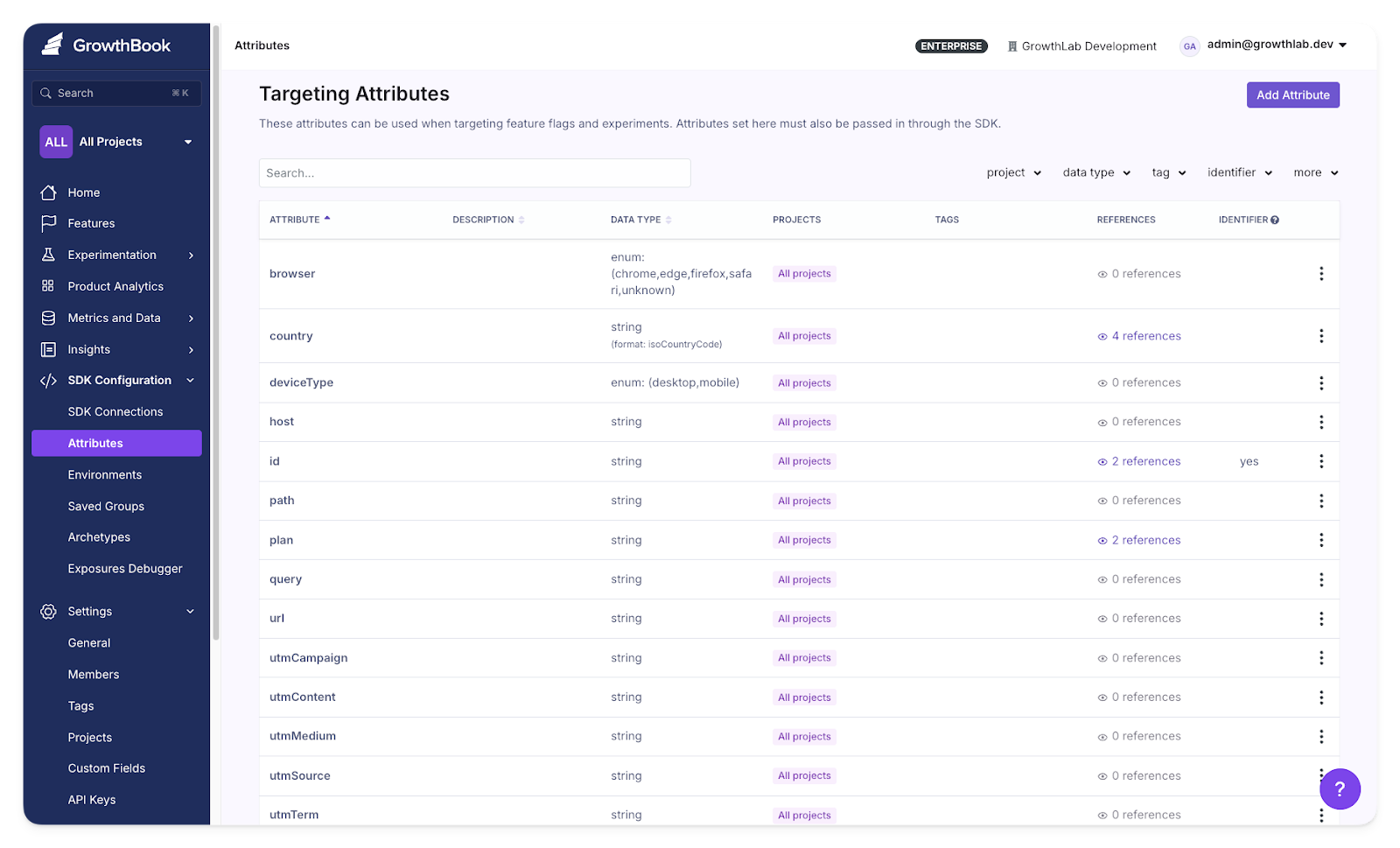
Target users based on specific attributes in GrowthBook
Entitlements and Access Control
If you run a multi-tier SaaS product, feature flags can manage which plans can access certain features. For example, you can automatically offer a premium integration for Enterprise users when they upgrade.
Also, if you need control over your data, use a feature flag platform that’s self-hosted or air-gapped. So, your flag evaluation data never leaves your network and ensures you’re compliant with regulations like HIPAA, GDPR, and SOC 2.
Refactoring Code
Feature flags reduce the risk of large-scale refactors by letting you run old and new implementations side by side. Route 5% of traffic to the refactored code path, compare outputs and performance against the original, and gradually shift over once you’re confident.
This is especially useful during monolith-to-microservices migrations, where you can flag-control which service handles each request and roll back individual routes without reverting the entire migration.
Compliance and Regulatory Control
Regulatory requirements change, sometimes quickly. Feature flags let you respond without waiting for a development cycle.
When a new data protection rule takes effect, you can disable a non-compliant feature across affected jurisdictions immediately. When your compliance team needs a four-eyes approval process for production changes, approval workflows on flag modifications implement that principle directly.
What Advanced Feature Flagging Strategies Can You Use?
Once you’re comfortable with basic on/off flags, you’ll quickly run into situations where a simple toggle isn’t enough. You need to roll out to a specific percentage of users. Or target enterprise accounts in a particular region.
These strategies build on each other. Here are a few examples:
Percentage Rollouts with Persistent Assignment
Percentage rollouts let you gradually release a feature to a random sample of users—5%, then 25%, then 50%—while monitoring for issues at each stage. The critical detail is persistent assignment.
When a user lands in the 10% cohort, they need to stay there as you ramp up to 50% and eventually 100%. Most platforms handle this by hashing the user’s ID against the flag key, which produces a consistent, deterministic assignment without storing state.
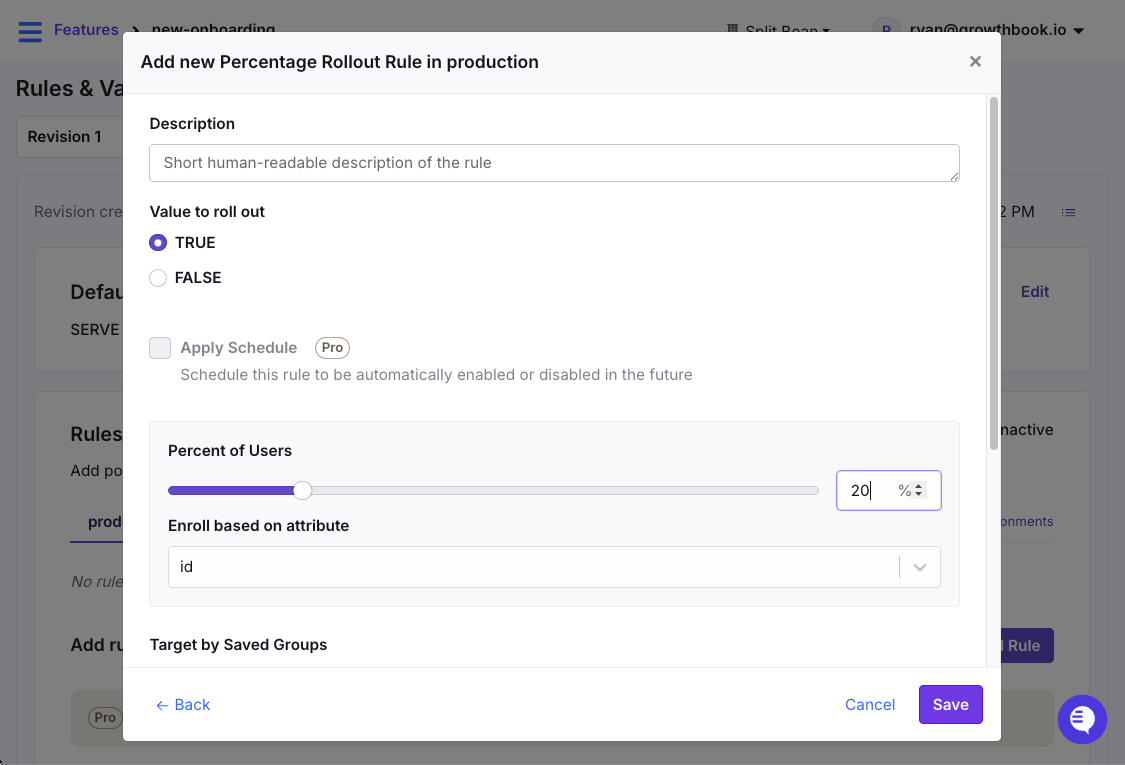
Release features using percentage rollouts in GrowthBook
Use percentage rollouts when you’re releasing a new feature and want to limit your blast radius. If something breaks at 5%, you’ve affected 5% of users.
Force Rules and Complex Targeting
Force rules let you target specific user segments based on combinations of attributes. For example, geography, device type, account age, company name, subscription tier, or any custom property you pass to your SDK.
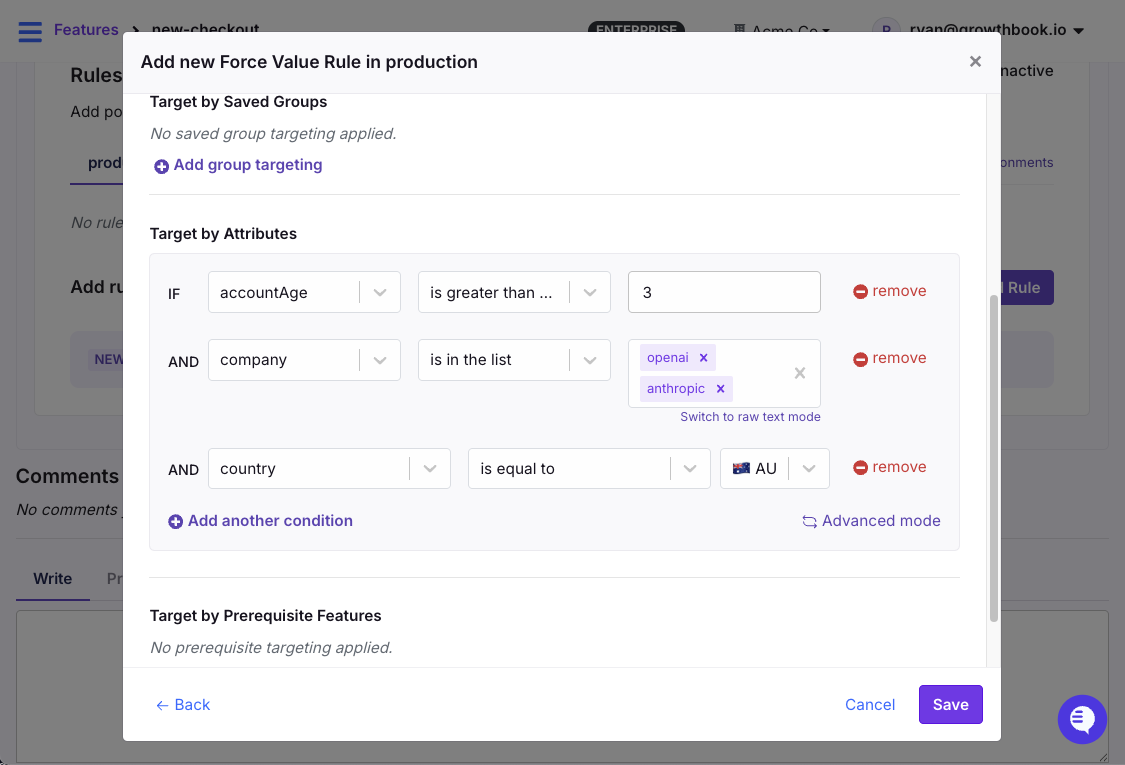
Target specific user segments using Force Rules in GrowthBook
For example, you might want to enable a feature for enterprise accounts in Australia with an account age of greater than three months. Or certain tax rules might only apply in a few countries.
Safe Rollouts with Guardrail Metrics
A safe rollout combines a percentage rollout with automatic metric monitoring. You define guardrail metrics like page load time, click rate, conversion rate, error rate, revenue per user, or whatever matters for this feature. And the system watches them as you ramp up.
If guardrails breach your thresholds, the rollout automatically reverses. The feature goes back to 0% while you investigate.
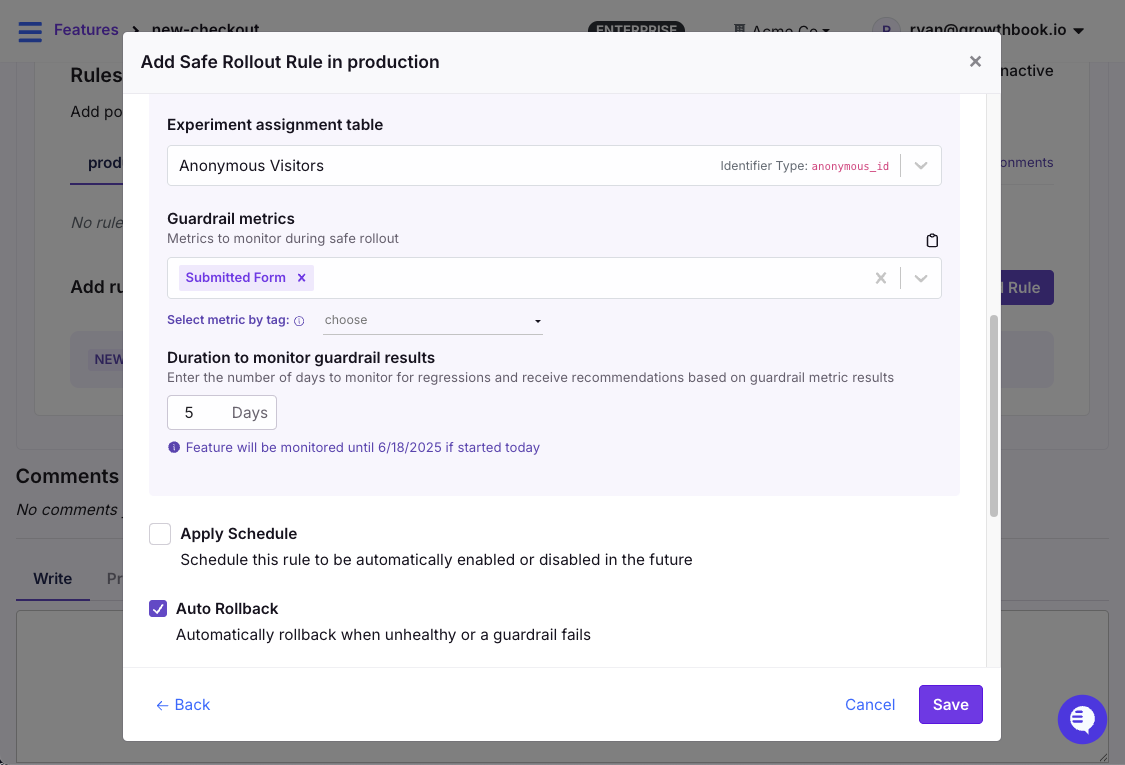
Monitor metrics in real time when using percentage rollouts in GrowthBook
Multi-Environment Flag Management
Your new checkout feature might need to be:
- Always on in development (so your team can build against it)
- 50% rollout in staging (to test the progressive rollout logic itself)
- Off in production (not ready for customers yet)
This is where the relationship between projects, environments, and SDK connections matters. In GrowthBook, projects are the top-level organizational unit (your mobile app vs. your web app).
Within each project, you have environments (production, staging, development). Each flag can have different values and rules per environment, and the SDK connection determines which flags your application actually receives.
When Should a Company Adopt Feature Flags?
The short answer is earlier than you think. Most teams wait until they’ve been burned by a botched deployment or a release that broke critical functionality. By that time, everything you do is reactive in nature—and you’re retrofitting them into a codebase that’s already complex.
If you’re seeing these signals, it’s definitely time to adopt feature flags:
- Every deployment feels high-stakes: Everyone’s on Slack watching dashboards, ready to hit rollback. If deploying makes your team nervous, you have a release process problem that flags can solve.
- Rollbacks take hours to complete: If your recovery time is measured in hours, a single toggle would have saved you time.
- Multiple teams are blocked on release windows: “We can’t ship until Backend deploys” shouldn’t be a weekly conversation. Using feature flags helps you decouple these dependencies.
- You can’t test with real production traffic: If you don’t have a way to expose features to real users in a controlled way before launching them, you’re guessing.
- Product decisions are based on opinions: You want to run A/B tests but lack the infrastructure to do so. In these cases, feature flags act as the delivery mechanism to make experimentation possible.
- You’re growing the engineering team: As your team grows, so does its deployment complexity. It’s easier to coordinate releases with two engineers, but when you add more to the mix, the room for errors increases.
- You deploy more than once a week (or want to): High-frequency deployment without feature flags is high-frequency risk. Flags make it safe.
If you checked 2+ of the above criteria, feature flags will immediately improve your workflow.
When Should You Not Use Feature Flags?
Knowing when not to use a flag is just as important as knowing when to use it. Here are a few reasons why you shouldn’t:
- Don’t use flags for static configuration: If changing the value requires a full restart, it belongs in your config, not your flag system. Feature flags are for runtime decisions, so mixing the two adds unnecessary complexity.
- Don’t use flags for secrets or sensitive data: You should never pass personally identifiable data (PII), API keys, or tokens through your feature flag system. This is especially critical for client-side applications because your configurations and targeting rules can be sent to the user’s browser, where anyone can inspect them. If you need to target based on sensitive attributes like email addresses, evaluate the flag server-side using verified data, or use hashed and anonymized attributes for client-side evaluation.
- Don’t use flags for core business logic: If your subscription tier logic or pricing rules permanently live inside a feature flag, your core business functionality now depends on the availability of an external flag service. Once an experiment or rollout is complete, migrate the winning variant into your application code or a dedicated entitlement service.
- Be cautious if your app traffic is low: Feature flags for simple on/off releases work at any scale. But if you’re planning to run A/B tests and your app has 100 users a month, you won’t reach statistical significance in any reasonable timeframe. The flag infrastructure still has value for release management and kill switches—just don’t expect experimentation to pay off until your traffic can support it.
- Don’t adopt flags without clear processes: Unless and until you have the right processes—for example, naming conventions, ownership docs, governance controls, and cleanup processes in place, don’t use flags. Otherwise, you’ll end up with too much technical debt in the long run.
What Are The Best Practices for Using Feature Flags?
To avoid spending months cleaning up avoidable issues, follow these best practices:
Use Clear, Descriptive Names
Six months from now, nobody will remember what ff-123 or test-flag means. So, choose a clear naming convention and stick to it. For example, {feature-name}-{type} works well (checkout-redesign-release, cta-color-experiment).
// ❌ Unclear - what does this control?
gb.isOn(“ff-123”)
gb.isOn(“test”)
gb.isOn(“experiment_2”)
gb.isOn(“new-thing”)
// ✅ Self-documenting
gb.isOn(“new-checkout-flow”)
gb.isOn(“holiday-2024-promo-banner”)
gb.isOn(“pricing-page-v2-experiment”)
gb.isOn(“premium-analytics-entitlement”)Note: Platforms like GrowthBook let you enforce naming patterns with regex validation to prevent duplication and enforce governance.
Clean Up Old Flags Ruthlessly
Every flag in your codebase adds a conditional branch. For instance, 10 flags create 1,024 possible code paths, but 20 flags create over a million. These create blind spots, so after you roll out a feature, do the following:
- Remove the flag check from your code
- Remove the old code path entirely
- Delete the flag from your management platform
- Document why it was removed
Turn it into a team ritual and also implement monthly or quarterly cleanup rituals to reduce technical debt. If you’re using a platform like GrowthBook, it’ll automatically detect stale flags and show you where these flags live in your codebase.
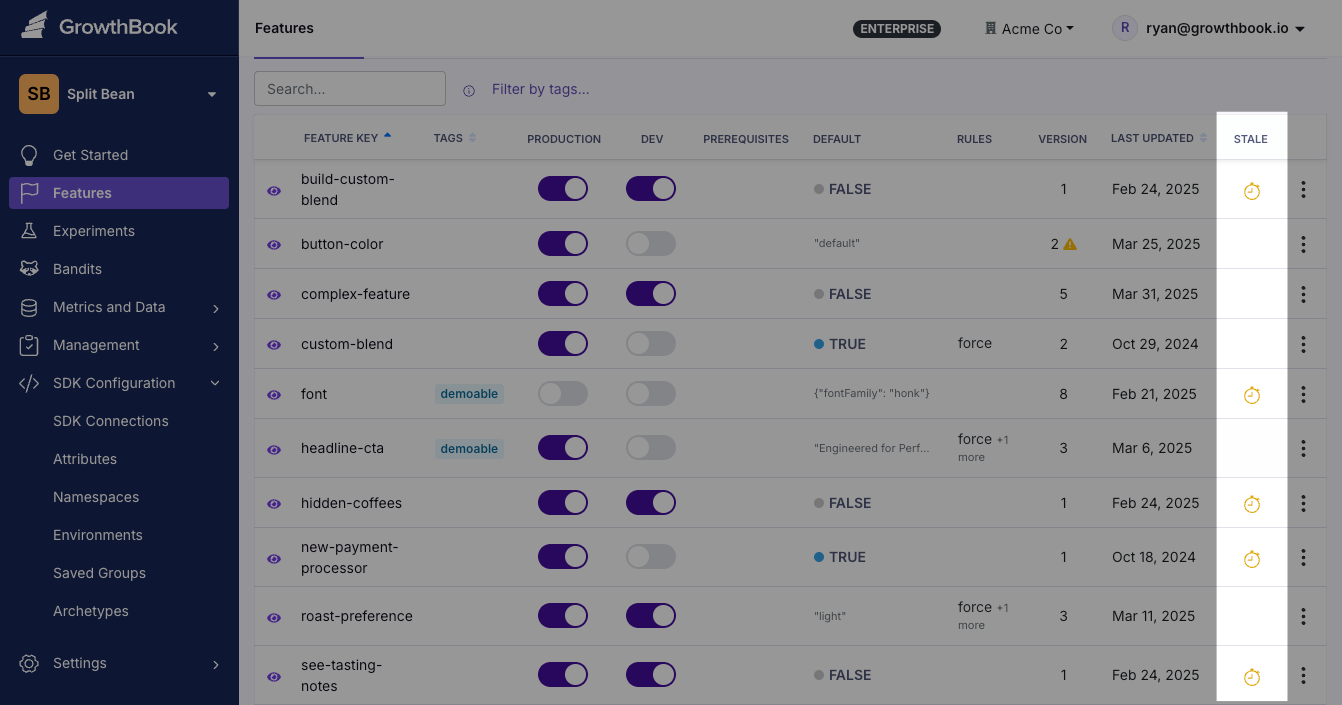
Remove old flags with automatic staleness detection in GrowthBook
Set Expiration Dates on Temporary Flags
It’s easy for seemingly temporary flags to become permanent. If there’s no clear deadline to clean it up, it’ll continue to sit in your codebase unnoticed—while its cleanup gets deprioritized sprint after sprint.
That’s why we recommend setting a calendar reminder for 30 or 60 days whenever you create a new flag. Better yet, create a Jira ticket or GitHub issue linked to the flag due two weeks after the target completion date.
Note: GrowthBook also supports flag scheduling, so you can set flags to automatically enable or disable at a specific date and time. This is useful for both feature launches and scheduled cleanup. If you prefer creating a Jira ticket, our Jira integration lets you link flags directly to tickets, so you can track these cleanup tasks within your existing workflow.
Start Small With Your Rollouts
It’s easy to skip steps when you’re confident about a feature. Resist the urge and default to a progressive delivery method.
Start with your internal team, then 1% of the traffic, then 10%, and so on. Continuously monitor changes or unusual behavior at each step—and only remove the flag when you confirm stability.
Monitor Business Metrics Too
A feature can do everything right. It can have zero errors or sub-100ms response times, but it can still tank your conversion rate.
When you set up monitoring for a rollout, watch both layers:
- Technical guardrails: Error rate, response time (p95 and p99), resource usage, API failures
- Business guardrails: Conversion rate, revenue per user, support ticket volume
If a new feature is technically flawless but users keep raising tickets right after launch, something’s wrong. You’ll have to look under the hood to understand what happened.
Document Flag Purpose and Ownership
You don’t want to be rummaging through hundreds of Slack threads or Jira tickets to find out what a flag does. At a minimum, every flag should have:
- What it controls (one sentence)
- Who owns it (team or individual)
- Expected cleanup date
- What metrics indicate a problem
- Rollback procedure (usually “set to 0%” or “disable“)
Template:
Flag: new-checkout-flow
Purpose: Progressive rollout of redesigned checkout experience
Owner: @growth-team (Primary: @jane)
Created: 2026-01-15
Expected cleanup: 2026-03-01
Rollback procedure: Set to 0% immediately if conversion drops >5%
Success metrics:
- Checkout completion rate improves by 3%+
- P95 checkout latency stays under 2s
- Support tickets don’t increase
Current status: 25% rollout, monitoring for 1 week before increasing
Use Role-Based Access Control
Role-based access control (RBAC) allows you to control which user can access specific flags. Use RBAC to define roles that map to your risk model, including who can:
- Create flags
- Modify targeting rules
- Approve changes to production
- Publish
When you combine RBAC with four-eyes approval workflows and audit logs, you’ll have everything you need to remain compliant.
Understand How Feature Flags Affect Performance
Feature flags add an evaluation step to every request, so you need to know where that evaluation happens and what it costs. Most modern SDKs run flag evaluations locally, including Growthbook..
On client-side implementations, the SDK initializes asynchronously, which means users may briefly see the default experience before flags are evaluated: a “flicker.” You can mitigate this through server-side rendering and anti-flicker support.
Similarly, if you have hundreds of flags with complex targeting rules, it can bloat the initial SDK payload. Within Growthbook, you can use project-scoping so each SDK connection receives only the relevant flags, and use Saved Groups to reference large ID lists rather than inlining them.
What Mistakes To Avoid While Using Feature Flags?
Here are the most common ways teams shoot themselves in the foot (and how to avoid it):
Reusing Flag Names
In 2012, Knight Capital dealt with a software glitch that bankrupted the company. When an engineer reused the name of a deprecated feature flag to launch a new feature, the app ran trades based on an old functionality. This happened because the old flag’s code was still present in an unpatched server and this mistake eventually cost the company $440 million, leading to its closure within a week.
It was one of the biggest coding errors we’ve ever seen. That’s why we recommend creating new flags for every feature you roll out. It takes 30 seconds, and you avoid the risk of activating code paths you or your team has forgotten about.
Using Client-Side Flags for Security
Feature flags control what to show. They don’t control who has permission. This distinction matters for client-side applications where flag values are visible in browser dev tools.
// ❌ WRONG: Anyone can enable this in browser dev tools
if (gb.isOn(“admin-panel”)) {
showAdminPanel();
}
// ✅ RIGHT: Verify permissions server-side
const isAdmin = await checkAdminPermissions(user.id);
if (isAdmin) {
showAdminPanel();
}If you’re doing anything involving money, data access, permission, or privileged APIs, you’re better off using server-side flags to do it.
Ignoring Rollback Procedures
Typically, rollbacks seem simple. You flip the flag back to off, and the problem is solved. But sometimes it’s not that simple. In 2020, Slack experienced an outage because a feature flag rollout triggered a performance bug. Even though the team rolled back the feature in 3 minutes, it left a stale HAProxy state that led to a six-hour outage.
Before rolling back a flag, you should know:
- What metrics indicate a problem
- Who has permission to roll back
- What the downstream effects of rollback might be
- Whether the rollback itself has been tested
Not Testing Both Flag States
Your Continuous Integration and Continuous Delivery (CI/CD) pipeline probably tests your application with your current production flag configuration. But does it test with the new flag turned on? Does it test with the new flag turned off again (the rollback scenario)?
If you only test one state, you’re assuming the other works. So, test three configurations:
- Current production state
- Intended release state
- Rollback state
If you can’t test all three in Continuous Integration (CI), at least smoke test the rollback in staging before you push the flag live.
How to Use Feature Flags for Experimentation
Most teams start with feature flags for release safety. But once you can control who sees what, a natural question follows: which version is actually better?
Without experimentation, you’re essentially shipping features based on intuition. For instance, you might think a signup form could be cleaner with fewer fields. But only a real test can tell you if there’s an uptick or fall in conversions. Feature flags give you the ability to run these tests easily.
How It Works
In GrowthBook, an experiment is a rule you add to an existing feature flag. You don’t need to migrate SDKs or add new code.
const variant = gb.getFeatureValue(“checkout-optimization”, “control”);
switch (variant) {
case “control”:
return <StandardCheckout />;
case “streamlined”:
return <StreamlinedCheckout />;
case “express”:
return <ExpressCheckout />;
}Users are randomly assigned to a variation and their assignment is stable—they always see the same version. GrowthBook tracks which variation each user saw, then joins that with your existing analytics events (purchases, signups, clicks) to calculate which version performed best.
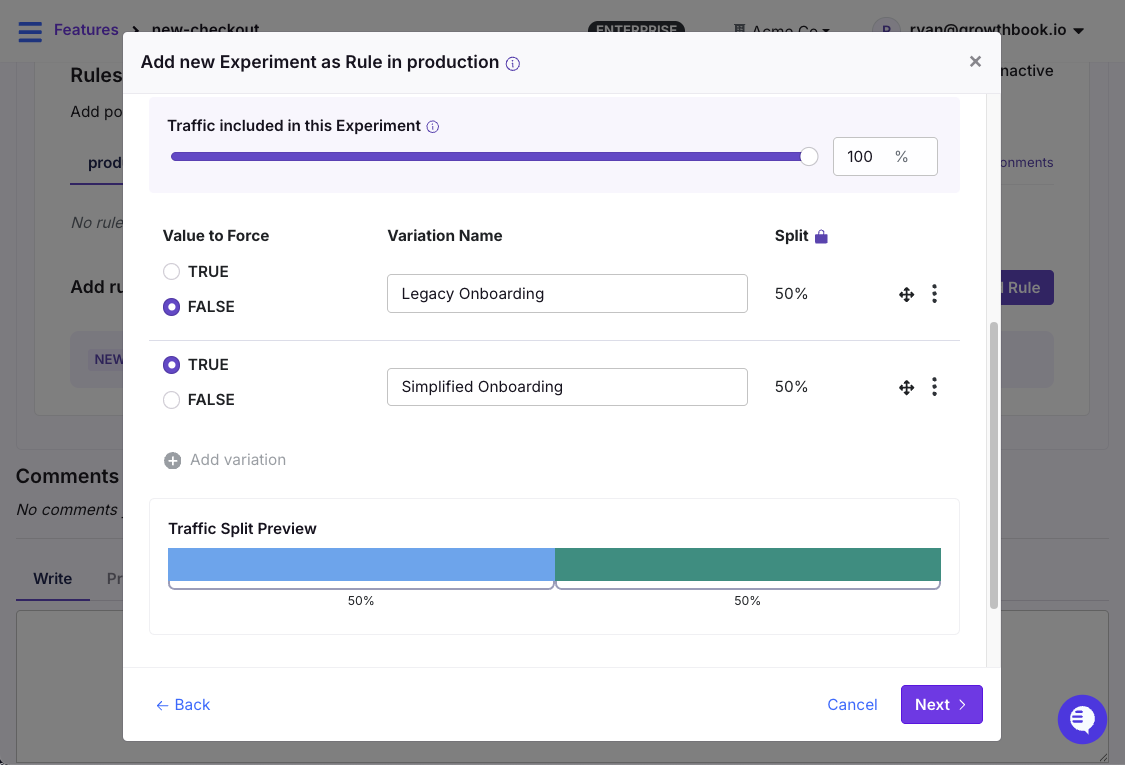
Run experiments using feature flags as the mechanism
The progression from flag to experiment typically looks like this:
- Simple toggle: Feature is on or off for everyone
- Percentage rollout: Feature reaches a growing slice of users
- Safe rollout: Percentage rollout with guardrail monitoring and auto-rollback
- Full A/B test: Controlled experiment with statistical analysis and winner selection
By the time you reach step 4, you already know the feature doesn’t break anything. Now you’re asking a different question: does it actually improve anything?
GrowthBook’s Warehouse-Native Approach
Most experimentation platforms require you to export data to their system, send tracking events to their infrastructure, or download results and crunch them in spreadsheets. All of these create data silos and increase costs.
That’s why GrowthBook connects directly to your existing data warehouse. You can integrate with platforms like Snowflake, BigQuery, Redshift, or Databricks and run the analysis there. Your data never leaves your infrastructure, which simplifies SOC 2, GDPR, and HIPAA compliance significantly.
And because it has access to your full warehouse, you can segment experiment results by any dimension you already track. For example, LTV cohort, acquisition channel, device type.
Should You Build or Buy a Feature Flagging Tool?
The answer depends on your organization’s size and needs. Here’s an easy framework to help you decide:
| Capability | Build Your Own | Use a Platform |
|---|---|---|
| Setup time | Hours | Minutes |
| Basic on/off flags | ✅ Easy | ✅ Easy |
| Percentage rollouts | ⚠️ Custom code | ✅ Built-in |
| User targeting | ⚠️ Custom code | ✅ Built-in |
| A/B testing | ❌ Requires analytics integration | ✅ Built-in |
| Non-engineer access | ❌ Not without building UI | ✅ Web dashboard |
| Audit logs | ❌ Custom implementation | ✅ Built-in |
| Multi-environment | ⚠️ Manual management | ✅ Built-in |
| SDKs for multiple languages | ❌ You build them | ✅ Provided |
| Ongoing maintenance | ⏰ Significant | ⏰ Minimal |
| Monthly cost | $0 (but engineering time) | $50-500+ (depends on scale) |
| Time to advanced features | Months of development | Immediate |
Legend: ✅ Fully supported | ⚠️ Possible with effort | ❌ Not practical
When To Build Your Own Feature Flag Tool
Building makes sense when your needs are genuinely simple:
- You need fewer than 10–20 simple on/off flags.
- You have strict compliance requirements preventing any third-party services.
- You have dedicated engineering time for ongoing maintenance.
- You only need basic on/off functionality without targeting or experimentation.
- You want full control and have the resources to maintain it.
A config file or a database table can work fine at this scale. But in our experience, before you know it, you’ll be building dashboards and complex functionality just to maintain the flags.
When To Use a Feature Flagging Platform
A platform pays for itself quickly once any of these apply:
- You need targeting beyond simple on/off (user segments, percentages, complex conditions).
- You want experimentation and A/B testing capabilities.
- You’d rather spend engineering time on your product than on internal infrastructure.
- Non-engineers (PMs, marketing, data analysts) need to manage flags.
- You require audit logs, role-based access, or compliance features.
- You want debugging tools, flag lifecycle management, or third-party integrations.
- You plan to scale flag usage across multiple teams and services.
Note: If you need to run experiments, it’s always better to go with a feature flagging platform. It’ll give you full control over what’s being tested, and you can be sure of its statistical rigor. For instance, GrowthBook includes a suite of developer tools for testing and debugging feature flags. The DevTools Chrome Extension lets you inspect flag evaluations and simulate different user attributes directly in your browser.
How To Create Feature Flags in GrowthBook
GrowthBook supports 23+ languages and frameworks. But here’s how to implement your first feature flag in under 10 minutes using React:
1. Get Your SDK Client Key
Go to SDK Configuration in GrowthBook, create a new SDK Connection, and copy the Client Key (it starts with sdk-).
2. Install the SDK
npm install @growthbook/growthbook-react
3. Wrap Your App With GrowthBook Provider
import { GrowthBook, GrowthBookProvider } from “@growthbook/growthbook-react”;
import { thirdPartyTrackingPlugin, autoAttributesPlugin } from “@growthbook/growthbook/plugins”;
// Create a GrowthBook instance
const gb = new GrowthBook({
clientKey: “sdk-abc123”, // Your SDK client key
enableDevMode: true, // Shows helpful debug info in development
plugins: [
thirdPartyTrackingPlugin(), // Optional, sends “Experiment Viewed” events via GrowthBook Managed Warehouse, Google Analytics, Google Tag Manager, and Segment.
autoAttributesPlugin(), // Optional, sets common attributes (browser, session_id, etc.)
],
});
// Load feature definitions from the GrowthBook API
gb.init();
export default function App() {
return (
<GrowthBookProvider growthbook={gb}>
<MyApp />
</GrowthBookProvider>
);
}4. Create a Flag in GrowthBook
In GrowthBook’s dashboard:
- Navigate to Features → Add Feature
- Set a unique feature key: new-onboarding
- Choose value type: boolean
- Default value is false (off by default)
Your flag is now live.
5. Use the Flag in Your Code
import { useFeatureIsOn } from “@growthbook/growthbook-react”;
function OnboardingFlow() {
const showNewOnboarding = useFeatureIsOn(“new-onboarding”);
if (showNewOnboarding) {
return <SimplifiedOnboarding />;
}
return <ClassicOnboarding />;
}That’s it. The flag defaults to false, so everyone sees the classic onboarding. Toggle it to true in the dashboard, and the new version appears instantly. Toggle it back, and you’ve rolled back in seconds.
From here, you can add targeting rules, percentage rollouts, safe rollouts with guardrail metrics, or full A/B experiments within the same dashboard, without changing your code.
Ready to start? Try GrowthBook Cloud free, or check out the documentation for integration guides across all 23+ SDKs. For self-hosting, the GitHub repo has everything you need.
Frequently Asked Questions
1. What is the difference between feature flags and feature management?
Feature flags are the technical mechanism—the if/else statements in your code that check configuration values. Feature management is the broader practice of using flags strategically across the software lifecycle, including targeting rules, progressive rollouts, experimentation, governance, and lifecycle management.
2. What is the difference between feature flags and feature toggles?
“Feature flags” and “feature toggles” are synonyms for the same concept. You’ll also see “feature switches,” “feature flippers,” and “feature gates.”
3. What is the difference between feature flags and experiments?
Feature flags control who sees what. Experiments measure which version performs better. So, flags act as the delivery mechanism to run your experiments, and experiments give you the measurement layer to see the results.
4. What is the difference between feature flags and branches?
Git branches manage code versions during development, while feature flags manage feature visibility in production. With branches alone, you can’t deploy a feature until the branch merges and deploys. But with feature flags, the code merges to main immediately, but the flag keeps it hidden until you’re ready to release.
5. What is feature testing?
Feature testing means validating that a feature works correctly before releasing it broadly. With feature flags, you can enable a feature only for QA accounts or internal users and test it in production with real data and traffic patterns.
6. How do feature flags help with continuous delivery?
Feature flags separate deployment from release, so you can merge code continuously and deploy multiple times a day with new features safely wrapped in flags. Without them, you can’t deploy continuously because the feature itself might be incomplete or unvalidated.
7. What is progressive delivery, and how do feature flags enable it?
Progressive delivery is the practice of gradually releasing features to larger user segments while monitoring for issues at each stage. Instead of a binary release (off for everyone, then on for everyone), you incrementally increase exposure. For example, releasing it to the internal team first, then 5% of real users, until you reach 100% of users.
8. How do feature flags differ from configuration files?
Configuration files are static. If you have to change them, you’ll have to redeploy the code or restart the whole service. But feature flags evaluate at runtime. You have to flip a switch to ensure your changes propagate to your application within seconds via streaming updates.
9. How can you deploy and manage feature flags at scale?
To deploy flags at scale, you need the following features and capabilities:
- Centralized feature flag management across all services
- SDKs for every language in your stack
- Streaming updates where changes propagate instantly
- Governance controls like audit logs, RBAC, and approval workflows
- Lifecycle management, such as stale flag detection, ownership tracking, and enforcement of cleanup cadence
10. What are client-side feature flags?
Client-side flags evaluate in the browser or mobile app rather than on your server. They’re useful for UI experiments, frontend rollouts, and A/B tests on visual elements. They’re usually visible to users, so don’t use them for PII, sensitive data, or access control.
11. What are the benefits of an open source feature flag platform?
Here’s why open source platforms are the better choice today:
- You can inspect exactly how flags are evaluated, how experiments are analyzed, and how your data is processed. Plus, you can audit security practices before deploying to production.
- You can fork the codebase if the project changes direction. You can also self-host indefinitely without an ongoing vendor relationship.
- You can deploy the app within your own infrastructure. This is critical for regulations like HIPAA, FedRAMP, SOC 2, and GDPR.
- With open source platforms, you pay for the infrastructure you choose, so you don’t rely on the vendor’s infrastructure pricing.
You can take advantage of OpenFeature, a Cloud Native Computing Foundation (CNCF) incubating project that creates a vendor-agnostic API standard for feature flagging.



