
Every team building on top of LLMs faces the same fundamental question: how do you know if your AI feature is actually good? For some products, the answer is straightforward. For others, it requires inventing an entirely new way to measure quality. Khan Academy's journey to A/B testing their AI tutor, Khanmigo, is one of the best examples I've seen of a team solving this hard measurement problem and then using experimentation to dramatically accelerate how fast they improve their product.
Dr. Kelli Hill, Head of Data at Khan Academy, recently joined us for a GrowthBook webinar to walk through their three-year journey from vibes-based prompt testing to rigorous A/B testing of GenAI features in production. Here's what stood out.
Sometimes Measuring AI Impact Is Easy
Sometimes the impact of AI on a product is straightforward to measure. When Typeform introduced an AI-powered form builder, their Chief Product and Technology Officer Alex Bass told us on The Experimentation Edge that it doubled their activation rate, the percentage of users who go from signing up all the way through to publishing a form and collecting data. Out of roughly 50 experiments Typeform ran, nothing else came close to that kind of impact.
In cases like Typeform, the metrics are clear. A user either publishes a form or they don't. The signal is clear and happens quickly. And you can measure it with the same metrics you were already tracking.
What Happens When the Output Is Harder to Evaluate
Khan Academy faced a fundamentally different challenge. Khanmigo is a generative AI-powered tutor that helps students work through math and other subjects. It's not a chatbot for entertainment. It's an educational tool used by students in classrooms. The bar is high: Khanmigo needs to be accurate, it needs to actually teach (not just give answers), and its tutoring quality needs to be measurable at scale.
That last part is the hard part. The same prompt can produce a dozen different responses. The underlying model changes regularly. A response that looks polished might actually reflect poor tutoring practice. And with nearly 200 million registered users and roughly a million daily active users on Khan Academy, they needed measurement that could operate at massive scale.
When Khanmigo first launched, the team had no way to rigorously evaluate quality. They started where everyone starts: reading outputs and making gut judgments. Kelli described their earliest eval work as "vibes-based prompt engineering" in Slack threads. It was useful for building intuition, but it didn't scale, it wasn't repeatable, and it couldn't tell them whether a change actually improved anything.
Turning Something Hard to Measure Into a Real Metric
The breakthrough was deciding to measure cognitive engagement, a construct from learning science research. Khan Academy adapted the ICAP framework (Interactive, Constructive, Active, Passive) published by Chi and Wylie in 2014. The original framework was designed for classrooms, so the team adapted it for AI tutoring interactions, focusing on questions like: who has the agency in help requests? How is the student processing Khanmigo's feedback? Who's driving the ownership of the learning?
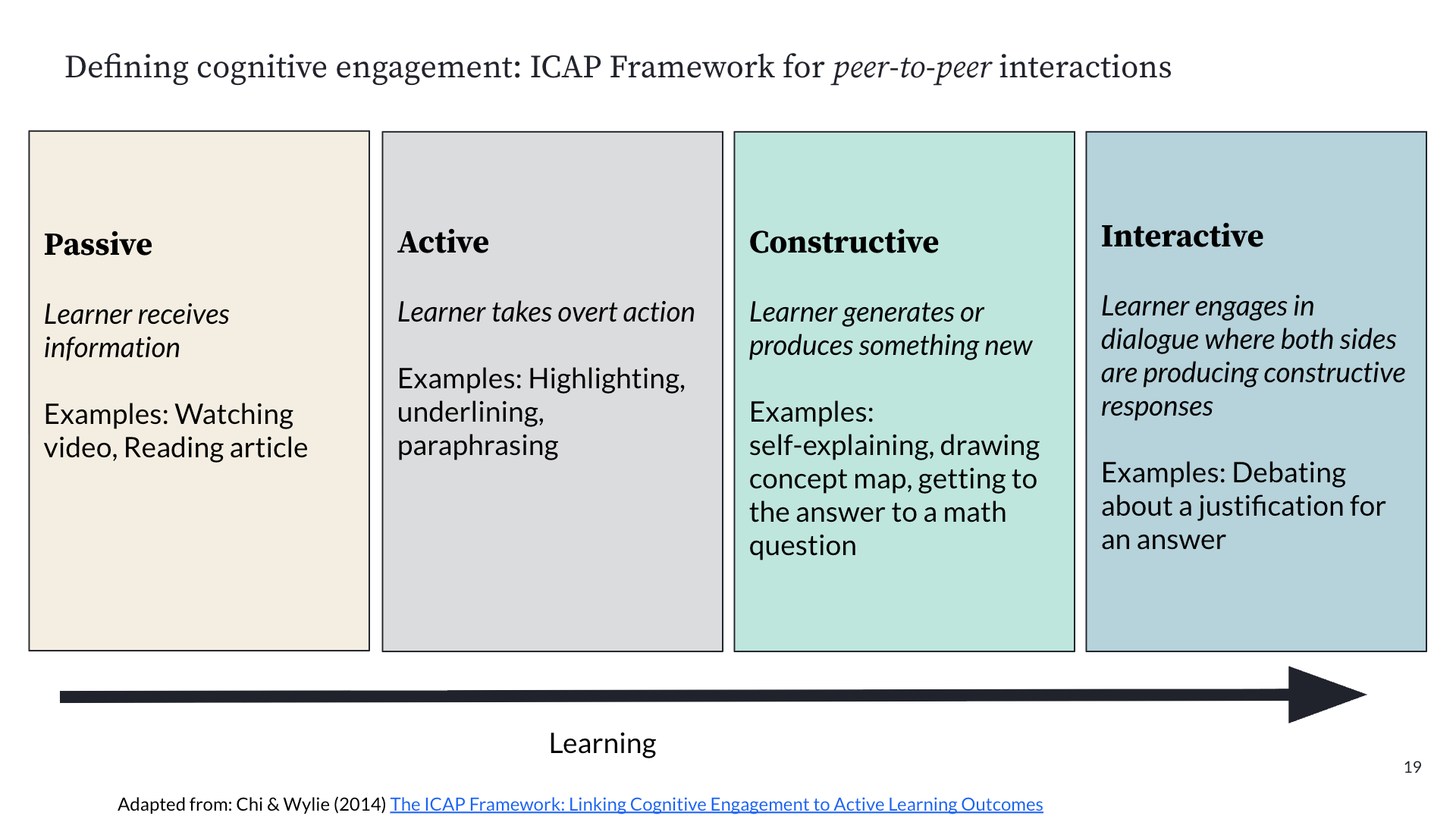
The key insight was that cognitive engagement isn't just an abstract academic concept. Khan Academy's prior efficacy research had already demonstrated that students who are more cognitively engaged on the platform get more skills to proficient, and that increased proficiency on Khan Academy transfers to higher scores on third-party assessments. So if they could measure cognitive engagement in Khanmigo conversations, they'd have a metric that actually predicted real learning outcomes.
Building the metric was the hardest part. Kelli was emphatic about this. The team defined a rubric, brought in subject matter experts, and had those experts hand-label student chat transcripts. They iterated on the rubric until they achieved 85% inter-rater agreement on a test dataset. Then they used the agreed-upon labels to create a ground truth dataset.
With ground truth in hand, they built an LLM-as-judge: an AI system that could automatically label transcripts using the same rubric. They fed the judge examples from the ground truth data, iterated on the prompt until the LLM judge's labels matched the human experts with high accuracy, and then scaled it. Today, they process about 20% of Khanmigo's chat data every night through this pipeline, feeding results into dashboards that the team monitors continuously.
Why This Unlocked A/B Testing for GenAI
Once Khan Academy had a reliable metric, they could finally do what they couldn't before: run controlled experiments on Khanmigo and measure whether changes actually improved tutoring quality.
Khan Academy uses GrowthBook for both feature flags and experimentation, self-hosted on top of their existing BigQuery data warehouse. They built additional infrastructure to randomize not just at the user level, but at the individual chat thread level, so each new Khanmigo conversation could be independently assigned to a treatment. This was critical because the unit of analysis for tutoring quality is a conversation, not a user.
The experiments they run aren't typical feature tests. They're testing different versions of a prompt, changes to system instructions, and even head-to-head model comparisons (Gemini vs. OpenAI models, for example). Kelli described it as "hill climbing": making very small, deliberate changes, sometimes just a single sentence in a prompt, and measuring whether cognitive engagement moves.
Their primary metrics are cognitive engagement and performance (are students getting more skills to proficient?). Their secondary and guardrail metrics include non-desirable behaviors (like giving the answer away), thread length, verbosity, and response latency. This layered approach ensures they're not accidentally improving one dimension while degrading another.
From Speed Bump to Safety Net
One of the most striking things Kelli shared was how the culture around experimentation shifted at Khan Academy. Before they had this infrastructure in place, experimentation was sometimes perceived as a speed bump, an extra hurdle before shipping. That's a common tension in product organizations.
But with GenAI, the calculus changed. LLM outputs are non-deterministic. A small prompt change can shift output dramatically. A response that looks better to a human reviewer might not reflect better tutoring. The AI tutor quality team at Khan Academy became the heaviest users of GrowthBook specifically because they realized that without A/B testing, they were relying on intuition in a domain where intuition consistently fails.
Kelli put it directly: experimentation went from being perceived as something that slows down shipping to being "a safety net" for understanding how changes actually perform across millions of users and prompts. The team now sees it as essential infrastructure, not overhead.
What This Means for Teams Building on LLMs
Khan Academy's journey illustrates a pattern that applies broadly. If you're building AI features, your path to effective experimentation runs through measurement. Sometimes you'll have a Typeform situation where existing metrics already capture the impact. But often, especially when the AI's output is complex or subjective, you'll need to invest in building new evaluation frameworks first.
The process Khan Academy followed is replicable: define a rubric grounded in domain expertise, get humans to agree on labels, build a ground truth dataset, train an LLM-as-judge, validate it, and scale it. It's not fast. Kelli described a three-year evolution from vibes testing to production A/B testing. But once you have that metric in place, the standard toolkit of A/B testing becomes incredibly powerful for improving AI features.
If you want to hear the full story, you can watch the webinar recording or or read the Khan Academy research paper. And if you're looking for an experimentation platform that can handle GenAI testing at scale, give GrowthBook a try.