

Most teams building with GenAI are flying blind. They've replaced unit tests with vibes and shipped prompts that "felt right" to three engineers on a Friday afternoon.
This isn't a criticism—it's a diagnosis. For decades, we operated under a deterministic paradigm. The contract between developer and machine was explicit: Input A + Code = Output B. Always, without fail. In this world, success was binary. A unit test passed or it failed.
Generative AI has shattered this contract. We have moved from deterministic engineering to probabilistic engineering. We are no longer building binaries; we are managing stochastic agents that produce a distribution of probable outputs. You cannot assert(x == y) when x and y can change every time.
Gian Segato (Anthropic) eloquently sums up this shift: “We are no longer guaranteed what x is going to be, and we're no longer certain about the output y either, because it's now drawn from a distribution…. Stop for a moment to realize what this means. When building on top of this technology, our products can now succeed in ways we’ve never even imagined, and fail in ways we never intended” (Building AI Products In The Probabilistic Era).
As seismic as this shift may be, we’re focusing on a single aspect of it here: the shift from the domain of verification (is it correct?) to the domain of validation (is it good?).
This shift has left teams scrambling to define quality. Many have fallen into the trap of thinking AI Evaluations (Evals) are a replacement for A/B testing. They aren't.
And, for those in a hurry, here’s the point:
- AI Evals check for competence—can the model do the job?
- A/B testing checks for value—do users care?
You cannot ship a good AI product without both AI Evals and A/B testing.
The Limits of Vibe Checking
In the early days of the LLM boom, “Prompt Engineering” was largely a feeling-based art. Devs would tweak a prompt, run it three times, read the output, and decide if it “felt” better.
This manual inspection—”vibe checking”—leverages human intuition, which is great for nuance but terrible for scale.
Vibe checking suffers from three critical flaws:
- Sample size: You might test 5 inputs. Production brings 50k edge cases.
- Regression invisibility: Making a prompt “polite” might accidentally break its ability to output valid JSON. You won’t feel that until the API breaks.
- Subjectivity: One engineer’s “concise” is another’s “curt.”
As ML Systems Researcher, Shreya Shankar notes, “You can’t vibe check your way to understanding what’s going on.” Manual inspection is mathematically insufficient for understanding probabilistic systems at scale.
To solve this, the industry turned to AI Evals.
What Are AI Evals?
AI Evaluations are an attempt to systematize the vibe check—turning qualitative judgment into quantitative metrics. They're a way to programmatically test the probabilistic parts of your application: prompts, models, and parameters.
But the term "Eval" is overloaded. When someone says "we're running evals," they might mean any of three things.
3 Types of AI Evals and Why They Matter
1. Model Evals
Model evals are benchmarks like MMLU or HumanEval. They're useful for choosing a provider (GPT-5 vs. Claude Opus 4.5), but they tell you almost nothing about your specific application. A model might ace GSM8K (math reasoning) and still be a terrible customer service agent. Worse, these public benchmarks are increasingly contaminated—models have seen the test questions during training, inflating scores that don't transfer to novel problems. (We wrote a whole article about why “The Benchmarks Are Lying To You.”)
2. System Evals
System evals are what matter most. These test your end-to-end pipeline: prompt + RAG retrieval + model. The key metrics here are things like hallucination rate, faithfulness (does the answer stick to the retrieved context?), and relevance.
Many teams now use LLM-as-Judge—a strong model grading outputs on subjective criteria like tone, helpfulness, and coherence. It scales better than human review, but inherits the same limitation: it measures whether an answer seems good, not whether users act on it.
3. Guardrails
Guardrails are real-time safety checks—toxicity filters, PII detection, jailbreak prevention. Important, but a different concern than quality.
All three share a critical constraint: they measure competence, not value. Whether you run evals offline in your CI/CD pipeline against a curated "Golden Dataset," or online against live traffic in shadow mode, you're still asking the same question: Can this model do the job?
Some evals do capture preference—human ratings, side-by-side comparisons, thumbs up/down. But these are still proxies. A user clicking "thumbs up" in a sandbox isn't the same as a user returning to your product tomorrow. Evals measure stated preference; A/B tests measure revealed preference through behavior.
What evals can't tell you is whether users will care enough to stick around.
Where Evals Fall Short
Even within the realm of evals, a model that looks good in controlled conditions can fall apart in production.
The DoorDash engineering team documented this problem in detail. They built a new ad-ranking model that performed well in testing—but when deployed to real users, its accuracy dropped by 4.3%. The culprit? Their test data was too clean. The model had been trained assuming it would always have fresh, up-to-date information about users. But in the real world, that data was often hours or days old due to system delays. The model had been optimized for conditions that didn't exist in production.
This principle applies even more to LLM applications. LLMs are sensitive to prompt phrasing, context length, and retrieval quality—all of which behave differently in production than in curated test sets.
Consider a concrete example: you optimize a customer service prompt for faithfulness—it sticks strictly to your knowledge base and never hallucinates. Evals look great. But in production, users find the responses robotic and impersonal. Satisfaction drops. You optimized for accuracy; they wanted empathy.
This is the core limitation of evals: they measure capability, not value. Even when you run evals against live traffic, you're testing whether the model can do something—not whether that something matters to users.
Why You Should Use A/B Testing with Your AI Evals
If evals are the unit test, A/B testing is the integration test with reality. It’s the only way to measure what actually matters: downstream business impact like retention, revenue, conversion, engagement, and user satisfaction.
But running A/B tests on LLMs introduces challenges that didn't exist in traditional web experimentation. (For an introduction to the topic, see our practical guide to A/B testing AI.)
Challenges of Running A/B Tests on AI
1. The Latency Confound
Intelligence usually costs speed. If you test a fast, simple model against a smart, slow one and the variant loses—why? Was the answer worse or did users just hate waiting three seconds?
Isolating "intelligence" as a variable often requires artificial latency injection: intentionally slowing the control to match the variant. Only then can you measure what you think you're measuring.
2. High Variance
LLMs are non-deterministic. Two users in the same variant might see meaningfully different responses. This noise demands larger sample sizes and longer test durations to reach statistical significance.
A button-color test might reach significance in a few thousand sessions. An LLM prompt test—where output variance is high and effect sizes are often small—might need 10x that, or weeks of runtime, to detect a meaningful difference.
3. Choosing the Right Metric
Choosing the right metric is harder for AI features than for traditional UI changes. A chatbot might increase engagement (users ask more questions) while decreasing efficiency (they take longer to get answers). Align your success metric with actual business value, not just surface activity.
These realities create a tension. A/B testing AI gives you certainty, but certainty takes time. If you have twenty prompts to evaluate, a traditional A/B test could take months. And during those months, a significant portion of your users are experiencing inferior variants.
Enter Multi-Armed Bandits
For prompt optimization—where iterations are cheap, and the cost of a suboptimal variant is low—multi-armed bandits offer a different trade-off. Instead of fixed traffic allocation, they dynamically shift users toward winning variants as data accumulates. You sacrifice some statistical rigor for speed and reduced regret.
Comparing A/B Testing to Multi-Armed Bandits
| Feature | A/B Testing | Multi-Armed Bandits |
|---|---|---|
| Primary Goal | Knowledge. Determine with statistical certainty if B is better than A. | Reward. Maximize total conversions during the experiment. |
| Traffic Allocation | Fixed for the duration. | Dynamic. Automatically shifts traffic to the winner. |
| Best Use Case | Major model launches, pricing, UI changes | Prompt optimization, headline testing |
Bandits aren't a replacement for A/B testing. They're a complement—best suited for rapid iteration loops where you're optimizing within a validated direction, not making major strategic bets.
How to Use AI Evals and A/B Testing Together
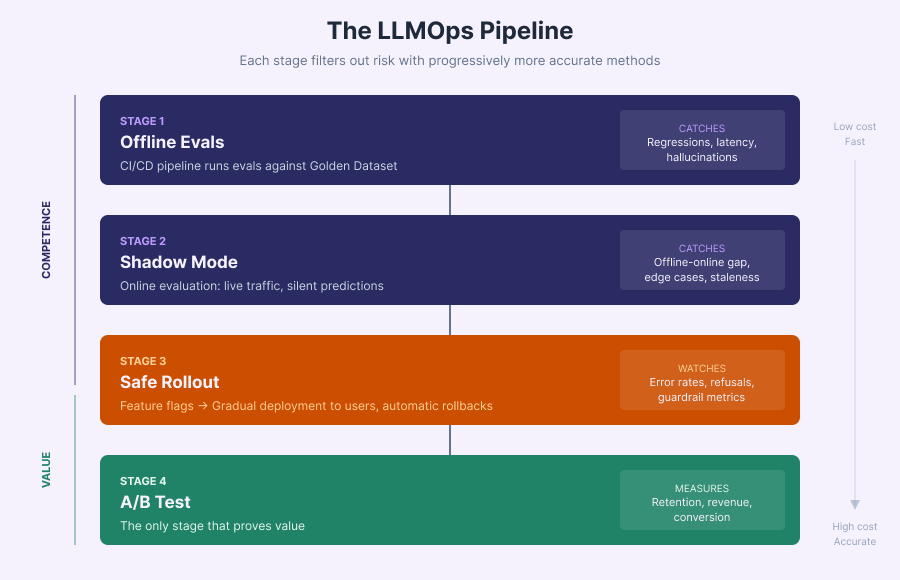
At GrowthBook, we see the highest-performing teams treating evals and experimentation not as separate islands, but as a continuous pipeline—each stage filtering out risk with progressively more expensive (but more accurate) methods.
Using AI Evals and A/B Testing Together in Practice
Stage 1: The Offline Filter (CI/CD)
A developer creates a new prompt branch. The CI/CD pipeline automatically runs evals against the Golden Dataset. If faithfulness drops below 90% or latency exceeds the threshold, the build fails. Bad ideas die here, costing pennies in API credits rather than user trust.
Stage 2: Shadow Mode (Production, Silent)
The prompt passes offline evals and gets deployed—but users never see it. The new model processes live traffic silently, logging predictions without surfacing them.
This is online evaluation: you're still measuring competence (latency, accuracy, edge case handling), but now against real-world conditions. DoorDash's 4% accuracy gap between testing and production is exactly the kind of discrepancy shadow mode is designed to surface—before users experience the degraded results.
Stage 3: Safe Rollout
Shadow mode passes. Feature flags gradually release the new model to users. You're monitoring guardrail metrics: error rates, refusal spikes, support tickets. If something tanks, you flip the flag and revert instantly—no code rollback required.
Stage 4: The A/B Test (Causal Proof)
The rollout survives. Now you run the real experiment: new model vs. baseline, measured on business metrics. Not "faithfulness" but retention. Not "relevance" but conversion. This is the only stage that proves value.
Conclusion: AI Evals plus A/B Testing for GenAI
You cannot A/B test a broken model. It’s reckless. And you cannot Eval your way to product-market fit. It’s guesswork.
To ship generative AI that's both safe and profitable, you need both: rigorous evals to ensure competence, and robust A/B testing to prove value. The pipeline between them—shadow mode, safe rollouts—is how you get from one to the other without breaking things.
As Segato warned, our products can now fail in ways we never intended. This pipeline is how we catch those failures before users do.
We've moved from is it correct? to is it good? Evals answer the first question. A/B tests answer the second. You need both.
Frequently Asked Questions
Can AI Evals replace A/B testing?
No. AI Evals and A/B testing serve different purposes in the development lifecycle. Evals measure competence—accuracy, safety, tone—whether run offline or online. A/B testing measures business value through revealed user behavior: retention, revenue, conversion. Evals tell you the model works; A/B tests tell you it's worth shipping.
What is the difference between Offline and Online Evaluation?
Offline evaluation happens pre-deployment using a static Golden Dataset to check for regressions and quality. Online evaluation happens in production using live traffic (e.g., shadow mode). Both measure competence, but online evaluation catches issues—like feature staleness or latency spikes—that don't appear in controlled conditions.
How do you handle latency when A/B testing LLMs?
Latency is a major confounding variable because "smarter" models are often slower. If a slower model performs worse, it's unclear if users disliked the answer or the wait time. To fix this, engineers use Artificial Latency Injection—intentionally slowing down the control group to match the variant's response time, isolating "intelligence" as the single variable.
What is "Vibe Checking" in AI development?
"Vibe checking" is the informal process of manually inspecting a few model outputs to see if they "feel" right. While useful for early exploration, it is unscalable and statistically flawed for production systems because it fails to account for edge cases, regressions, or large-scale user preferences.
When should I use a Multi-Armed Bandit instead of an A/B test?
Use a Multi-Armed Bandit when your goal is optimization (maximizing reward) rather than knowledge (statistical significance). MABs are ideal for testing prompt variations or content recommendations because they automatically route traffic to the winning variation, minimizing regret. Use A/B tests for major architectural changes or risky launches where you need certainty.
What is the best way to deploy AI models safely?
Use a staged pipeline. Start with offline evals in CI/CD to catch regressions. Then use shadow mode to test against live traffic silently. Next, use feature flags to release to a small percentage of users while monitoring guardrails. Finally, run a full A/B test to measure business impact. Each stage filters out risk before exposing users to problems.
What is LLM-as-Judge?
LLM-as-Judge is an evaluation technique where a strong model (like GPT-4 or Claude) grades the outputs of your system on subjective criteria such as tone, helpfulness, and coherence. It scales better than human review but shares the same limitation as other evals: it measures whether an answer seems good, not whether users will act on it.
What is the difference between stated and revealed preference in AI evaluation?
Stated preference is what users say they like—thumbs up ratings, side-by-side comparisons in a sandbox. Revealed preference is what users actually do—returning to your product, completing tasks, converting. Evals capture stated preference; A/B tests capture revealed preference. The two often diverge.


